
Saisi en juillet 2023 par les bureaux de l’Assemblée nationale et du Sénat pour étudier les nouveaux développements de l’intelligence artificielle dans le contexte de la révolution de l’IA générative, l’office parlementaire sur les choix scientifiques a rendu son rapport qui tente, à la fois, de dresser un bilan des technologies d’intelligence artificielle et d’anticiper les tendances qui se dégagent.
Ce rapport retrace les développements technologiques des différents modèles d’IA et le détail de leur fonctionnement, identifie leurs enjeux politiques, économiques, sociétaux, culturels et scientifiques, et aborde les questions de régulation, comparant la stratégie nationale française en IA à près de 20 autres, six dans l’Union européenne et onze dans le reste du monde, et en analysant une dizaine de projets de gouvernance mondiale de l’intelligence artificielle. Il propose en conclusion 18 recommandations, dont cinq à soutenir dans le cadre du Sommet pour l’action sur l’IA (Paris les 10 et 11 février 2025).
La diffusion de l’intelligence artificielle, surtout de l’IA générative, permet de rendre automatisables nos tâches intellectuelles, et certaines de nos compétences dans le domaine de la création sont directement concurrencées.
Sommaire
LES RÉGIMES JURIDIQUES DE LA PROPRIÉTÉ INTELLECTUELLE
Les régimes juridiques de propriété intellectuelle existants font face à des défis qu’ils n’ont jamais rencontrés auparavant. Ils sont incapables, d’une part, de permettre la rémunération ou l’indemnisation des titulaires de droit sur les oeuvres ayant servi de sources aux modèles d’IA, d’autre part, de déterminer, pour l’heure, les règles applicables aux oeuvres créées par intelligence artificielle, dont le statut reste incertain.
En outre, l’automatisation des processus de création artistique est susceptible de modifier en profondeur l’ensemble des industries culturelles, en permettant aux studios de créer des contenus rapidement et à moindre coût.
1. Des régimes de propriété intellectuelle fragilisés
L’intelligence artificielle a d’ores et déjà un impact sur les régimes de propriété intellectuelle, aussi bien sur le droit d’auteur français que sur le copyright anglo-saxon, qui bien que convergents sur la forme depuis la convention de Berne de 1886 restent différents. En effet, il n’existe toujours pas de droit d’auteur au niveau international.
Pour mémoire, le droit d’auteur français considère une oeuvre comme une extension de la personnalité de son créateur, conférant un droit de propriété incorporel fort, qui englobe des attributs d’ordre intellectuel, moral et patrimonial.
Le droit moral est ainsi perpétuel, inaliénable et imprescriptible même si le droit patrimonial, d’une durée variable, a fait tomber l’oeuvre dans le domaine public.
En revanche, le copyright relève d’une logique strictement économique et accorde un droit moral restreint, qui se concentre principalement sur le support matériel de l’oeuvre et les intérêts financiers du titulaire du copyright (qui peut être l’auteur ou pas). Des modalités de régime juridique différentes peuvent également exister d’un pays à un autre.
Entraîner un modèle d’intelligence artificielle nécessite de grandes quantités de données, collectées de manière automatique à travers de vastes jeux de données, qui contiennent donc parfois tout ou partie d’oeuvres soumises au copyright ou au droit d’auteur.
Sans transparence de la part des développeurs de modèles de fondation, il est difficile de savoir exactement quelles oeuvres sont présentes au sein des données d’entraînement du modèle. Il est donc difficile pour un ayant droit de faire valoir ses droits pour atteinte au copyright ou au droit d’auteur.
Cela est d’autant plus problématique que la directive 2019/790 du 17 avril 2019 de l’Union européenne prévoit paradoxalement une possibilité pour les ayants droit de refuser (« opt-out ») que leurs oeuvres soient utilisées dans les bases de données d’IA. Un droit de retrait qui ne peut donc rester que formel.
Alexandra Bensamoun, professeure de droit à l’Université Paris-Saclay et spécialiste du droit d’auteur et de l’intelligence artificielle, a affirmé lors de son audition devant la commission de la culture, de l’éducation et de la communication du Sénat que l’on sait aujourd’hui que des modèles d’IA ont utilisé dans leurs données d’entraînement des données d’auteurs qui avaient pourtant d’ores et déjà fait valoir leur droit de retrait des bases de données.
L’absence de respect des règles relatives à la propriété intellectuelle est également reconnue par les représentants des grandes entreprises américaines de l’intelligence artificielle eux-mêmes. Ils ne se cachent pas de violer le droit d’auteur ou le copyright, dès lors que les oeuvres sont sur Internet. Ainsi, le directeur technique d’OpenAI, Mustafa Suleyman, a pu avouer :
« Je pense qu’en ce qui concerne le contenu qui se trouve déjà sur le Web ouvert, le contrat social de ce contenu depuis les années 1990 est l’utilisation équitable. Tout le monde peut le copier, le recréer, le reproduire. C’est ce que l’on appelle le “freeware” si l’on veut, et c’est ce que l’on a compris ».
Cette question relevant principalement du sujet des données utilisées, la Commission nationale de l’informatique et des libertés (Cnil) est directement concernée par ces questions. Lors de son audition par les rapporteurs, Bertrand Pailhès, directeur des technologies et de l’innovation à la Cnil et ancien coordinateur national pour l’intelligence artificielle, a rappelé que le règlement général pour la protection des données (RGPD) doit s’appliquer à l’entraînement des modèles d’intelligence artificielle.
Aussi, en théorie, la collecte de contenus ne peut se faire en provenance de sources manifestement illégales. La collecte de données doit en outre répondre à une finalité explicitement définie et s’appuyer sur une base légale, souvent l’intérêt légitime. La Cnil a constitué des « fiches pratiques » qui permettent d’assurer le respect de la protection des données lors de leur traitement par des systèmes d’IA, ce qui inclut donc, sans s’y limiter, la protection de la propriété intellectuelle.
La base de données d’entraînement du contenu illicite ?
Les législations françaises et européennes déterminent ainsi un cadre théorique assez clair pour le respect de la propriété intellectuelle et fixent des limites aux cas d’entraînement des modèles d’intelligence artificielle. Elles permettent de définir ce qui constitue des pratiques acceptables ou pas.
Cela est d’autant plus important qu’il semble que beaucoup d’entreprises développant des solutions d’intelligence artificielle semblent tentées de contourner ces principes. Ces discours se retrouvent en effet souvent dans le secteur du numérique, y compris du côté de figures emblématiques de la French Tech, comme Oussama Ammar, cofondateur de l’incubateur The Family avec Alice Zagury et Nicolas Colin, qui a souvent fait de la transgression des règles le coeur de ses conseils aux start-up en vue d’une innovation disruptive.
Néanmoins, fixer des règles définissant ce cadre légal n’est pas en soi suffisant, il faut également s’assurer de disposer des moyens permettant de contraindre les entreprises de respecter ce cadre.
Or, les sociétés font elles-mêmes valoir des principes de confidentialité qui contreviennent à cet objectif, ce qui pose un problème de transparence de l’information.
Il est quasi impossible pour les autorités ou pour un juge d’obtenir des informations sur les bases de données d’entraînement utilisées sans y avoir directement accès et il est donc très difficile de prouver, sur la seule base des résultats d’un modèle, que ce dernier contient dans sa base de données d’entraînement du contenu illicite. Et quand bien même le régulateur ou un juge aurait accès aux milliards de données utilisées, le tri pour identifier les oeuvres protégées resterait lui aussi très ardu.
Les entreprises développant des modèles de fondation considèrent, de plus, que les données collectées et leur traitement avant même l’entraînement (nettoyage/curation) constituent une source de valeur pour elles. Ouvrir ces données constituerait pour elles une perte d’avantages comparatifs vis-à-vis de leurs concurrents.
C’est cette position qu’ont tenue les responsables de MistralAI lors de leur audition devant les rapporteurs. Il y a donc un équilibre à trouver entre, d’une part, l’intérêt général et la préservation des intérêts des ayants droit, le régulateur ou les titulaires des droits devant pouvoir avoir accéder aux bases de données d’entraînement des modèles d’IA, et, d’autre part, les intérêts des entreprises développant les modèles d’IA pour qui ces données d’entraînement sont un élément de valeur en soi et une ressource indispensable pour l’entraînement des modèles.
Des risques contentieux
Dans ce contexte d’incertitudes, les risques contentieux sont de plus en plus grands, qu’il s’agisse de l’utilisation d’oeuvres protégées pour entraîner les modèles, de la protection des oeuvres générées par des systèmes d’IA ou, encore, de tout autre litige qui pourrait émerger. En l’absence de règles claires, il reviendra aux juges de trancher les litiges. Le rôle de la jurisprudence sera donc central et laisse les artistes, les entreprises et les utilisateurs dans un flou juridique anxiogène, avec des risques financiers qui ne sont pas négligeables.
C’est pourquoi une clarification de ces enjeux et des régimes juridiques applicables est indispensable. Le rapport d’information de la commission des lois de l’Assemblée nationale déposé en conclusion des travaux de sa mission d’information sur les défis de l’intelligence artificielle générative en matière de protection des données personnelles et d’utilisation du contenu généré fournit des pistes utiles à la réflexion.
Le modèle économique de la création artistique par l’IA
Par définition, le système de droit d’auteur se retrouve davantage fragilisé par l’apparition d’oeuvres générées par l’IA que le système de copyright.
En effet, le premier rattache l’oeuvre à son auteur avant de poser la question du titulaire du droit patrimonial. Or, la définition de l’auteur dans le cas d’une oeuvre créée par un modèle d’IA est difficile. Qui est l’auteur d’une oeuvre générée par IA ? L’auteur est-il le développeur du modèle de fondation, le distributeur de l’application d’IA générative, l’utilisateur qui a formulé une instruction ou, de manière plus complexe, l’ensemble des auteurs qui ont vu leurs oeuvres être utilisées pour l’entraînement du modèle et parvenir à l’oeuvre finale ?
Ces questions appellent à réfléchir à la notion même de droit d’auteur qui, s’il apparaît de moins en moins adapté, doit tout de même être sanctuarisé à l’heure de l’IA générative, fusse au prix d’importantes adaptations.
Les rapporteurs ont rencontré des artistes créateurs d’oeuvres utilisant l’IA : le collectif d’artistes Obvious, représenté par Pierre Fautrel, ainsi que Christophe Labarde, organisateur de l’exposition « Irruption – Quand l’intelligence artificielle bouleverse la création » au Château de Turenne. Pour mémoire, le collectif Obvious est notamment à l’origine de l’oeuvre générée par IA « La famille de Belamy », vendue aux enchères pour un prix de 432 000 dollars, ce qui a constitué un record.
Ces deux experts ont admis qu’il était trop difficile de déterminer si une oeuvre réalisée par l’IA était inspirée d’une oeuvre déjà existante, sauf à tomber dans la pure et simple copie, la contrefaçon étant déjà un délit puni par la loi
Une solution minimale pour réguler les créations par l’intelligence artificielle pourrait être l’application d’un filigrane sur les médias créés par des modèles d’intelligence artificielle (watermarking).
Ainsi, il serait possible de distinguer les oeuvres générées par des modèles d’IA et celles d’origine humaine. Une telle solution se heurte néanmoins à des problèmes pratiques : il faudrait que le filigrane ne soit pas trop visible afin de ne pas dénaturer l’oeuvre ; la modification de l’oeuvre ne devrait plus être possible après l’application du filigrane pour ne pas altérer ce dernier ou le faire disparaître ; il faudrait que le filigrane puisse être détecté sur différents supports, numériques et physiques. Restera en outre la question de savoir comment appliquer de tels filigranes à différents types d’oeuvres : textes, images, sons, musiques, vidéos en tout genre générés par intelligence artificielle.
Autant de défis qui feront l’identification concrète des oeuvres créées par des systèmes d’intelligence artificielle un sujet complexe et multidimensionnel, au moins à ce stade de l’état des connaissances et des techniques.
L’avenir de la création artistique
L’arrivée d’outils d’intelligence artificielle capables de générer du contenu artistique sur la base de données numériques, couplée à l’avènement du Big Data, sont des facteurs de transformation profonde de la création artistique et de l’ensemble des industries culturelles qui pourront créer du contenu plus rapidement, plus efficacement et à moindre coût grâce à l’IA générative, avec une offre plus personnalisée par l’analyse des données des utilisateurs.
Aux États-Unis, les rapporteurs ont rencontré Matthieu Lorrain et Surya Tubach, représentants de Google Creativ, la filiale de Google en charge des industries culturelles, qui leur ont parlé des initiatives prises par le géant du numérique en matière de création artistique. Ils affirment que le futur consistera par exemple à produire des « contenus liquides » (liquid content), à savoir des contenus adaptables aux préférences des utilisateurs grâce à des intelligences artificielles capables d’analyser toutes les données produites par les utilisateurs.
Face à un tel modèle économique et technique, il pourrait devenir difficile aux productions traditionnelles de rivaliser avec ces types de contenu spécifiquement conçus pour répondre aux attentes de chaque utilisateur. Il s’agirait alors d’un pas supplémentaire vers la marchandisation des industries culturelles, notamment audiovisuelles, en faisant notamment disparaître la vision d’auteur des films et des séries.
La perspective unique et très personnelle que peut apporter un réalisateur talentueux pourrait ne plus exister par exemple. Il ne s’agirait plus que de créer des contenus audiovisuels sur mesure, basés sur les « préférences » supposées des utilisateurs.
En plus de brider la créativité artistique, ce type de contenu conduirait paradoxalement à renforcer les bulles de filtres et mènerait à une plus grande uniformisation des films et des séries, limitées à une déclinaison de tropes narratifs populaires moyens ajustés à l’aide d’artefacts superficiels de personnalisation basés sur les préférences supposées du spectateur.
Une telle évolution cloisonnerait encore davantage chacun dans un univers culturel aux perspectives restreintes et aux contenus appauvris. Avant même le recours généralisé à l’IA, les contenus et les recommandations de plateformes audiovisuelles telles que Netflix vont déjà en partie dans ce sens.
De telles transformations profondes de la création artistique et des industries culturelles entraîneront de manière très probable une forte conflictualité sociale, comme l’ont montré les longues grèves de syndicats de scénaristes aux États-Unis, soutenues par différentes corporations d’artistes, dont celle des acteurs.
La grève de la Writers Guild of America en 2023 avec ses 11 500 scénaristes face à l’Alliance of Motion Picture and Television Producers a ainsi duré du 2 mai au 27 septembre 2023, ce qui est historique.
UNE POLITIQUE FRANÇAISE DE L’INTELLIGENCE ARTIFICIELLE EN DEMI-TEINTE
La stratégie nationale en faveur de l’IA depuis 2017 : un retard à l’allumage
Des stratégies nationales ambitieuses pour le secteur numérique ont déjà été définies par le passé. Le « Plan Calcul », lancé en 1966, le rapport sur l’informatisation de la société publié en 1978, qui a inventé le concept de télématique et proposé le lancement du réseau Minitel, le plan « Informatique pour tous » impulsé en 1985, le rapport sur les autoroutes de l’information en 1994 ou encore le programme d’action gouvernemental pour la société de l’information (PAGSI) et les espaces publics numériques (EPN) en 2000, en sont différents exemples qui ont souvent laissé des souvenirs doux-amers en raison de leurs résultats qui n’étaient pas à la hauteur des espoirs suscités.
En France, le pouvoir exécutif a depuis 2017, sans directement réguler l’intelligence artificielle, annoncé des stratégies nationales pour l’IA et mis en place une série de mesures concernant la gouvernance de l’IA. Refaire l’histoire de cette succession d’annonces ou de mesures dans le domaine des technologies d’intelligence artificielle est indispensable avant de pouvoir dessiner des perspectives pour le futur.
Une première stratégie nationale pour l’IA a été voulue par le Président de la République, alors François Hollande, dès janvier 2017, en écho à la stratégie américaine dévoilée en octobre 2016 par le président américain Barack Obama.
La secrétaire d’État chargée du numérique et de l’innovation, Axelle Lemaire, avait ainsi été missionnée pour préparer les détails de ce plan baptisé « France IA », lancé dans l’incubateur Agoranov le 20 janvier 2017 et ayant conduit à la remise d’un rapport au Président de la République à la Cité des Sciences et de l’industrie le 21 mars 2017.
Ce plan visait notamment à mettre en place un comité de pilotage « France IA », à financer de nouveaux projets de recherche en IA à travers le programme pour les investissements d’avenir (PIA), à créer un centre interdisciplinaire sur l’IA, à réaliser une cartographie de l’écosystème de l’intelligence artificielle en France en vue de mobiliser les acteurs publics et privés, à réfléchir à des normes et des standards, et à suivre l’impact de l’IA sur l’économie et la société.
En parallèle de ce plan gouvernemental, dès le printemps 2016, la sénatrice Dominique Gillot et le député Claude de Ganay ont préparé le premier rapport de l’OPECST sur l’intelligence artificielle. Publié le 15 mars 2017, ce rapport présentait 15 propositions au nom de l’Office. Ses auteurs y regrettaient qu’en raison de l’actualité, le plan France IA arrive trop tard pour pouvoir être réellement pris en compte dans les politiques publiques.
Le plan France IA du Gouvernement a ensuite été suspendu puis a été purement et simplement enterré : il n’a pu en effet être mis en oeuvre dans le contexte des élections présidentielles de 2017 et de l’élection d’Emmanuel Macron à la tête de l’État.
Ce dernier a préféré retravailler une nouvelle stratégie pour l’intelligence artificielle durant son premier mandat, qu’il annoncerait lui-même : un an plus tard c’est avec la remise d’un autre rapport émanant du président de l’Office, notre ancien collègue député Cédric Villani, alors en mission pour l’exécutif, que le Président de la République a pu proposer au Collège de France, le 29 mars 2018, en présence de la ministre allemande de la recherche et du commissaire européen à l’innovation, une « Stratégie nationale et européenne pour l’intelligence artificielle », lors d’un événement baptisé « AI for Humanity »
Rétrospectivement, cette approche semblait se préoccuper insuffisamment de l’innovation technique en IA, le rapport de notre ancien collègue était d’ailleurs exclusivement tourné vers les technologies de Deep Learning en vogue à l’époque et appelait essentiellement à centrer les efforts de notre stratégie en matière d’intelligence artificielle sur leur déploiement dans certains domaines d’application comme les transports, la santé, la sécurité, l’environnement et la défense.
En matière de santé, il proposait par exemple d’interconnecter les fichiers déjà existants pour développer ce qui est devenu le Health Data Hub.
Avec un financement pluriannuel d’1,5 milliard d’euros annoncé, la stratégie nationale pour l’IA ambitionnait de faire de la France un des leaders mondiaux de l’intelligence artificielle.
Or, elle a surtout consisté dans la labellisation de quatre instituts interdisciplinaires d’intelligence artificielle (3IA), le financement de chaires et de doctorats ou encore l’investissement indispensable dans des infrastructures de calcul à travers des supercalculateurs gérés par le GENCI (pour Grand équipement national de calcul intensif) comme Jean Zay, inauguré en 2019, ou Adastra, inauguré en 2023, et dont les performances atteignent respectivement 36,85 pétaflops et 74 pétaflops (Jean Zay devrait toutefois atteindre 125,9 pétaflops cette année). Pour mémoire un pétaflop représente un million de milliards de calculs d’opérations en virgule flottante par seconde.
Il faut noter que ces deux supercalculateurs n’étant plus au niveau exascale des standards internationaux, c’est-à-dire dépassant un exaflop par seconde (un milliard de milliards de calculs par seconde), la France va héberger un supercalculateur européen (qui devait s’appeler Jules Verne mais portera finalement le nom de la chercheuse oubliée Alice Recoque) dont elle devra partager l’usage avec l’Union européenne.
À titre de comparaison, l’entreprise d’Elon Musk spécialisée en IA, appelée « xAI » et qui développe le système Grok, s’est engagée à acheter entre 3 et 4 milliards de dollars de GPU à Nvidia et s’est dotée d’un supercalculateur de 150 MW du nom de Colossus, construit en 19 jours, développant théoriquement 3,4 exaflops par seconde, car composé de 100 000 processeurs Nvidia Hopper 100. Sa taille devrait doubler d’ici quelques mois pour atteindre 200 000 processeurs.
Pour mémoire, Google, OpenAI, Microsoft, Meta et Nvidia étaient les seules entreprises au monde à dépasser les 50 000 GPU et xAI vient de repousser la frontière du concevable avec la perspective de cette structure de 200 000 processeurs GPU. Les puces utilisées, les Nvidia Hopper H100, ont un coût unitaire qui varie de 30 000 à 70 000 dollars, un coût du même ordre que la nouvelle génération de puces Nvidia, les Blackwell B200, dont les rapporteurs ont pu voir le format réduit au siège de Nvidia, et qui seront commercialisées prochainement.
Les 200 000 processeurs de xAI ont une valeur comprise entre 6 et 14 milliards de dollars environ. Le supercalculateur Jean Zay, après son extension prévue d’ici la fin de l’année 2024, sera quant à lui doté de 1 456 GPU Nvidia H100.
La stratégie nationale pour l’intelligence artificielle, divisée en deux phases, a également conduit à une coordination qui n’a d’interministérielle que le nom avec un coordinateur rattaché initialement à la direction interministérielle du numérique et du système d’information et de communication (DINSIC), puis à la direction générale des entreprises (DGE) du ministère de l’économie, sans autorité réelle sur les conditions de mise en oeuvre de la stratégie.
L’instabilité du titulaire de cette fonction et les vacances répétées du poste sont également frappantes : Bertrand Pailhès nommé en juillet 2018, quitte ses fonctions un an plus tard en novembre 2019, il n’est remplacé par Renaud Vedel qu’en mars 2020, qui ne reste chargé de cette mission que jusqu’à l’été 2022, Guillaume Avrin ne rejoint la structure qu’en janvier 2023, à nouveau après une vacance de six mois. Cette instabilité et ces vacances révèlent une fonction problématique et mal définie.
Au total, le pilotage de la stratégie nationale en IA reste toujours défaillant : elle demeure d’ailleurs en réalité toujours sans pilote, évoluant au gré des annonces du Président de la République, à l’instar de son courrier du 25 mars 2024 faisant d’Anne Bouverot « l’envoyée spéciale du Président de la République » pour le futur sommet sur l’IA ou de son discours lors du rassemblement des plus grands talents français de l’IA à l’Élysée le 21 mai 2024, qui présentait les nouveaux cinq grands domaines de la stratégie nationale pour l’IA.
Le bilan critique de la stratégie et son évaluation par la Cour des comptes
La première étape de la stratégie nationale pour l’IA mise en place par l’exécutif à partir de 2018 a déjà pu être évaluée et les effets produits par les mesures prises ont pu être comparés à leurs effets escomptés.
La Cour des comptes a ainsi publié, en avril 2023, un rapport qui dresse le bilan de la stratégie mise en place par l’exécutif concernant l’intelligence artificielle. Elle évalue en particulier les mesures prises et leurs effets par rapport aux objectifs fixés par le Président de la République lors de la mise en place de ce plan : positionner la France parmi les cinq meilleurs pays en termes d’IA, et devenir les chefs de file européens dans le domaine.
L’évaluation est plutôt mitigée. En effet, loin d’atteindre les objectifs affichés, comme celui de devenir un leader mondial, il semble que la stratégie nationale pour l’IA ait surtout permis à la France de ne pas décrocher davantage dans la compétition au niveau mondial, au moins dans les quelques domaines investis par le plan.
La Cour des comptes affirme ainsi que la priorité donnée à la recherche en IA a permis à la France de maintenir un niveau honorable en termes de publication d’articles scientifiques et d’efficience de la recherche.
Ce résultat est cependant à relativiser puisque lorsque ces classements sont rapportés au PIB, la position de la France chute au 44e rang : « Si la France apparaît assez performante en matière de recherche en IA (10e rang mondial et 2e rang européen en 2021 en nombre de publications en IA sur un total de 47 pays comparés), sa recherche dans ce domaine apparaît peu efficiente au regard du produit intérieur brut de la France (44e rang mondial et 25e européen en 2021 pour le même critère rapporté au PIB). »
La mise en place des Instituts 3IA est jugée plutôt efficace par le rapport, qui constate que ces instituts contribuent à l’augmentation du nombre de publications scientifiques et de coopérations internationales en matière d’IA. Ceci est permis grâce à des collaborations interdisciplinaires et à l’acquisition de ressources technologiques avancées. Un exemple est l’acquisition de noeud de clusters GPU par le 3IA de Nice Sophia-Antipolis pour renforcer ses capacités de calcul ; il est mis à disposition en priorité pour les chaires 3IA.
Le rapport note toutefois que les résultats des Instituts 3IA ne sont pas à la hauteur des attentes initiales. D’après la Cour des comptes, la cartographie des formations en IA, loin d’être homogène, est complexe et peu lisible. De plus, les instituts 3IA ne sont pas autonomes et apparaissent précaires : la pérennité des financements de l’État est cruciale pour maintenir la dynamique de ces instituts, or la visibilité des perspectives financières est très réduite.
En raison de ce contexte global, le rapport juge que la formation des talents en IA, même si elle a progressé, reste encore très insuffisante pour combler le déficit de compétences en intelligence artificielle dans le pays. Les rapporteurs ajoutent que rien n’a non plus été fait pour lutter contre la fuite des cerveaux.
S’agissant de la gouvernance et des investissements en IA, la complexité de l’écosystème d’acteurs et des outils de financement public constitue un frein à l’efficacité des mesures voulues par l’exécutif, et ce, malgré la présence du coordinateur national à l’intelligence artificielle (aujourd’hui Guillaume Avrin). Cette coordination ne joue pas un rôle assez important et n’est pas assez financée selon la Cour.
Ce déficit de cohérence dans la gouvernance française de sa stratégie en IA crée des difficultés pour attirer et concentrer les investissements. Aussi, bien que les sommes investies représentent des montants importants, la dispersion des moyens dans un saupoudrage peu rationnel empêche ces investissements d’être pleinement efficaces.
Aussi, la Cour des comptes préconise l’élaboration d’une nouvelle politique publique globale en matière d’IA, au moins pour assurer une bonne gouvernance et une coordination de l’ensemble des dispositifs de financement.
Les perspectives de relance de la politique nationale de l’IA
La dernière étape concernant la gouvernance française de l’intelligence artificielle a été la remise au Gouvernement du rapport « IA : notre ambition pour la France » le 13 mars 2024
Ce rapport a été rédigé par la Commission de l’intelligence artificielle dont les présidents étaient Anne Bouverot et Philippe Aghion, rencontrés par les rapporteurs, tout comme l’ont été les deux rapporteurs généraux du rapport, Cyprien Canivenc et Arno Amabile.
Ce rapport important contient 25 recommandations pour une politique ambitieuse de la France en matière d’IA, avec un investissement d’un peu plus de cinq milliards d’euros par an sur cinq ans. Ces dépenses évaluées à 27 milliards d’euros au total sont récapitulées ci-après.
Tableau récapitulatif des recommandations de la Commission de l’intelligence artificielle
| Recommandations | Coût estimé sur cinq ans | |
| 1 | Créer les conditions d’une appropriation collective de l’IA et de ses enjeux afin de définir collectivement les conditions dans lesquelles elle s’insère dans notre société et nos vies quotidiennes | 10 millions d’euros |
| 2 | Investir dans l’observation, les études et la recherche sur les impacts des systèmes d’IA sur la quantité et la qualité de l’emploi | 5 millions d’euros |
| 3 | Faire du dialogue social et professionnel un outil de co-construction des usages et de régulation des risques des systèmes d’IA | – |
| 4 | Porter une stratégie de soutien à l’écosystème d’IA ouverte au niveau international en soutenant l’utilisation et le développement de systèmes d’IA ouverts et les capacités d’inspection et d’évaluation par des tiers | – |
| 5 | Faire de la France un pionnier de l’IA en renforçant la transparence environnementale, la recherche dans des modèles à faible impact, et l’utilisation de l’IA au service des transitions énergétique et environnementale | 100 millions d’euros |
| 6 | Généraliser le déploiement de l’IA dans toutes les formations d’enseignement supérieur et acculturer les élèves dans l’enseignement secondaire pour rendre accessibles et attractives les formations spécialisées | 1,2 milliard d’euros |
| 7 | Investir dans la formation professionnelle continue des travailleurs et dans les dispositifs de formation autour de l’IA | 200 millions d’euros |
| 8 | Former les professions créatives à l’IA, dès les premières années de l’enseignement supérieur et en continu | 20 millions d’euros |
| 9 | Renforcer la capacité technique et l’infrastructure du numérique public afin de définir et de passer à l’échelle une réelle transformation des services publics grâce au numérique et à l’IA, pour les agents et au service des usagers | 5,5 milliards d’euros |
| 10 | Faciliter la circulation des données et le partage de pratiques pour tirer les bénéfices de l’IA dans les soins, améliorer l’offre et le quotidien des soignants | 3 milliards d’euros |
| 11 | Encourager l’utilisation individuelle, l’expérimentation à grande échelle et l’évaluation des outils d’IA pour renforcer le service public de l’éducation et améliorer le quotidien des équipes pédagogiques | 1 milliard d’euros |
| 12 | Investir massivement dans les entreprises du numérique et la transformation des entreprises pour soutenir l’écosystème français de l’IA et en faire l’un des premiers mondiaux | 3,6 milliards d’euros |
| 13 | Accélérer l’émergence d’une filière européenne de composants semi-conducteurs adaptés aux systèmes d’IA | 7,7 milliards d’euros |
| 14 | Faire de la France et de l’Europe un pôle majeur de la puissance de calcul installée | 1 milliard d’euros |
| 15 | Transformer notre approche de la donnée personnelle pour mieux innover | 16 millions d’euros |
| 16 | Mettre en place une infrastructure technique favorisant la mise en relation entre les développeurs d’IA et les détenteurs de données culturelles patrimoniales | 35 millions d’euros |
| 17 | Mettre en oeuvre et évaluer les obligations de transparence prévues par le règlement européen sur l’IA en encourageant le développement de standards et d’une infrastructure adaptée | – |
| 18 | Attirer et retenir des talents de stature internationale avec des compétences scientifiques ou entrepreneuriales et managériales dans le domaine de l’IA | 10 millions d’euros |
| 19 | Assumer le principe d’une « Exception IA » sous la forme d’une expérimentation dans la recherche publique pour en renforcer l’attractivité | 1,025 milliard d’euros |
| 20 | Inciter, faciliter et amplifier le recours aux outils d’IA dans l’économie française en favorisant l’usage de solutions européennes | 2,6 milliards d’euros |
| 21 | Faciliter l’appropriation et l’accélération des usages de l’IA dans la culture et les médias pour limiter la polarisation entre grands groupes et petits acteurs et lutter contre la désinformation | 60 millions d’euros |
| 22 | Structurer une initiative diplomatique cohérente et concrète visant la fondation d’une gouvernance mondiale de l’IA | 300 millions d’euros |
| 23 | Structurer dès maintenant un puissant écosystème national de gouvernance de l’IA | 5 millions d’euros |
| 24 | Doter la France et l’Europe d’un écosystème d’évaluation public et privé des systèmes d’IA au plus proche des usages et des derniers développements technologiques | 15 millions d’euros |
| 25 | Anticiper les concentrations de marché sur l’ensemble de la chaîne de valeur de l’intelligence artificielle | – |
| TOTAL | 27 milliards d’euros | |
Les principaux leviers d’action actuels de l’exécutif sont ceux de la deuxième phase de la stratégie nationale pour l’intelligence artificielle (2021-2025), ainsi que les compléments apportés à cette stratégie par les mesures annoncées par le Président de la République lors du « rassemblement des plus grands talents français de l’IA » à l’Élysée le 21 mai 2024.
Lors de son audition par les rapporteurs, Guillaume Avrin, coordinateur national pour l’IA, a détaillé la structure du dispositif mis en place pour favoriser l’IA dans notre pays. Il a précisé que le plan de l’exécutif se découpait en plusieurs phases. La première phrase, aujourd’hui terminée consistait d’abord à promouvoir une IA d’excellence notamment grâce à la création des Instituts 3IA. Le second volet, en cours de déploiement, censé couvrir la période 2021-2025, consiste à diffuser l’IA dans l’économie et la société à l’aide de trois moyens d’investissement : la commande publique, les subventions et l’investissement en capital.
Le développement de cette deuxième phase vise spécifiquement quatre domaines : l’IA frugale, soit l’IA compétitive tout en étant écologiquement responsable, l’IA embarquée, c’est-à-dire des systèmes pouvant être exécutés localement, l’IA de confiance et l’IA générative, des aspects thématiques bien plus mis en avant que lors de la première phase. Le souhait de l’exécutif est de développer l’interdisciplinarité pour l’IA en promouvant l’initiative « l’IA plus X », c’est-à-dire l’utilisation de l’IA comme outil dans divers secteurs. L’approche applicative semble donc très privilégiée par le gouvernement, ce qui a été confirmé par l’audition de la DGE.
Lors du rassemblement des plus grands talents français de l’IA à l’Élysée le 21 mai 2024, le Président de la République, Emmanuel Macron, a indiqué qu’il souhaitait voir la stratégie en matière d’IA se déployer autour de cinq grands domaines : les talents, les infrastructures, les usages, l’investissement et la gouvernance. Une telle approche est plus satisfaisante qu’une concentration sur les seules applications.
Il a annoncé un plan d’investissement de 400 millions d’euros pour financer neuf pôles d’excellence en IA, comprenant les quatre anciens Instituts 3IA lancés en 2019 (MIAI@Grenoble-Alpes, 3IA Côte d’Azur, PRAIRIE et ANITI) auxquels s’ajoutent désormais SequoIA à Rennes, un projet de l’université de Lorraine, Hi Paris! de l’Institut polytechnique de Paris, PostGenAI@Paris de la Sorbonne et DATA IA de l’Université Paris-Saclay, l’objectif étant de passer de 40 000 à 100 000 personnes formées à l’IA par an.
Un autre projet annoncé par le chef de l’État est « Scribe » d’une durée prévue de deux ans, inclus dans le plan France 2030 et visant à soutenir l’IA sectorielle. Ce plan vise à encourager le développement de modèles de fondation et des applications sectorielles de l’IA, la création de jeux de données d’alignement sectoriels et le développement d’outils d’évaluation et de sécurité.
Un nouveau fonds d’investissement devrait être mis en place, dont un quart sera financé par l’État afin de financer des domaines aujourd’hui moins en vue, voire oubliés, bien que pourtant indispensables à l’IA, comme la filière des semi-conducteurs et des puces ainsi que l’informatique en nuage. Cet aspect est à suivre de près.
Le Président de la République a dans le même temps annoncé vouloir créer des fonds d’investissement similaires au niveau européen avec le même objectif de financement de ces secteurs stratégiques. Il faut espérer qu’une telle démarche ne conduise pas à prendre encore davantage de retard dans la mise en oeuvre d’un financement urgent et ciblé en direction de la filière française des semi-conducteurs et des puces ainsi que de l’informatique en nuage.
Le Président de la République a également prévu de doter le Conseil national du numérique de 10 millions d’euros supplémentaires pour lui permettre de réaliser sa mission d’acculturation des citoyens à l’IA, notamment à travers les « Cafés IA », proposés par la commission de l’intelligence artificielle.
Enfin, l’ouverture du centre d’évaluation en IA au sein du Laboratoire national de métrologie et d’essai (LNE) confirme le rôle important joué par cette structure dans le suivi et l’évaluation des modèles d’IA, en lien avec les exigences posées par l’AI Act de l’UE en 2024. Ce texte prévoit en effet un cadre assez précis en la matière.
18 recommandations complémentaires sur l’IA
En plus des recommandations générales concernant les nouveaux développements de l’intelligence artificielle, les rapporteurs ont également des recommandations plus spécifiquement destinées au Président de la République et aux organisateurs du futur sommet des 10 et 11 février 2025 de l’intelligence artificielle. Ces recommandations visent à s’assurer qu’une vision française éclairée de l’intelligence artificielle pourra s’exprimer à travers ce sommet.
Les rapporteurs ont élaboré 18 recommandations, dont cinq sont consacrées à la préparation du prochain sommet sur l’intelligence artificielle que la France organisera les 10 et 11 février 2025. Ils ont choisi de limiter le nombre de préconisations de manière à pouvoir communiquer plus efficacement. Ils demandent au gouvernement et au Président de la République de traduire ces recommandations en mesures effectives rapidement opérationnelles.
LES PROPOSITIONS À SOUTENIR DANS LE CADRE DU FUTUR SOMMET DE L’IA
1. Faire reconnaître le principe d’une approche transversale de l’IA et renoncer à l’approche exclusivement tournée vers les risques
La France doit profiter de l’organisation du prochain sommet pour contribuer à établir, selon une approche transversale, un cadre international de référence pour la future gouvernance mondiale des systèmes d’intelligence artificielle. Les sommets pour la sécurité de l’intelligence artificielle (AI safety summits) se sont tenus à la suite d’une initiative britannique visant à anticiper et encadrer les risques de l’intelligence artificielle dont les risques existentiels, il faut maintenant aller plus loin.
Le Sommet pour l’action sur l’IA des 10 et 11 février 2025 doit avoir le souci d’élargir les problématiques abordées et de poser les jalons de cette gouvernance mondiale. C’est pourquoi au-delà de la sécurité, il faut mettre à profit le fait que cinq thèmes essentiels seront l’objet du sommet (l’IA au service de l’intérêt public avec la question des infrastructures ouvertes ; l’avenir du travail ; la culture ; l’IA de confiance ; la gouvernance mondiale de l’IA) pour faire accepter au plus haut niveau le principe d’une approche transversale des enjeux de l’IA, qui devra se matérialiser solennellement dans une déclaration finale des participants.
La France étant chargée de l’organisation du sommet, elle pourra non seulement élargir ponctuellement les problématiques et les perspectives du travail collectif mais surtout consacrer cette logique multidimensionnelle des problématiques de l’IA. Les interrogations sur les risques existentiels de l’IA, dont la concrétisation reste très incertaine, ne doivent pas prendre une part trop grande au sein de cet événement international et des futurs sommets : il convient plutôt de se préoccuper d’enjeux plus directs. En effet, les systèmes d’intelligence artificielle présentent d’ores et déjà des risques réels et certains.
L’Office a déjà eu l’occasion de consacrer plusieurs travaux à ce sujet, notamment son rapport pionnier de 2017, où il se prononçait en faveur d’une intelligence artificielle maîtrisée, utile et démystifiée, prônant l’usage éthique d’algorithmes sûrs, transparents et non discriminatoires. Il y réclamait une politique publique de l’intelligence artificielle permettant la diffusion de ces technologies dans l’économie et la société française, à travers une politique de formation initiale et continue ambitieuse, une vigilance à l’égard de la domination par la recherche privée et les entreprises américaines et l’organisation de grands débats publics évoluant en fonction de l’état de l’art de la recherche en la matière.
Nous estimons à cet égard que les cinq thèmes retenus pour le prochain sommet de l’IA éludent deux dimensions à prendre en compte de manière prioritaire :
– l’éducation, qui pourrait être ajoutée à la verticale « culture » avec pour intitulé « éducation et culture » ;
– la souveraineté numérique, qui pourrait être ajoutée à la verticale « l’IA au service de l’intérêt public » avec pour intitulé « souveraineté numérique et intérêt général ».
2. Proposer de placer la gouvernance mondiale de l’IA sous l’égide d’une seule organisation internationale
Ce sommet doit être l’occasion d’apporter un minimum de clarification et de rationalisation dans la dizaine de projets de gouvernance mondiale de l’IA, c’est pourquoi il est proposé de placer la gouvernance mondiale de l’IA sous l’égide d’une seule organisation internationale, à savoir l’ONU, seule organisation pleinement légitime sur le plan multilatéral.
L’importance et la spécificité du sujet invitent à créer une nouvelle institution spécialisée membre du système des Nations unies, dont les compétences s’étendraient de la coordination internationale de la régulation de l’IA à la lutte contre la fracture numérique mondiale, plutôt qu’à confier ces responsabilités à une agence internationale déjà existante.
Ce serait la suite logique du Pacte numérique mondial, du comité scientifique international sur l’IA et du dialogue mondial sur la gouvernance de l’IA que les Nations unies ont mis en place, en septembre 2024.
Il s’agit aussi de l’une des propositions formulées par plusieurs chercheurs qui ont évoqué différentes pistes de gouvernance internationale de l’IA. L’approche de l’OCDE doit nourrir le travail de cette future organisation internationale de l’IA.
3. Initier le cadre d’une régulation globale et multidimensionnelle de l’IA en s’inspirant des travaux de l’OCDE et de l’UE
L’approche de la régulation mondiale de l’IA doit être multidimensionnelle, ainsi que le présent rapport dans ses développements sur la chaîne de valeur de l’IA ou, différemment, les travaux de l’OCDE le prévoient. L’OCDE ne reprend pas l’idée de chaîne de valeur telle qu’elle est développée dans le présent rapport mais elle propose de distinguer la multidimensionnalité de l’IA selon plusieurs phases.
Puisque les modèles d’IA se décomposent en au moins quatre phases distinctes et interdépendantes (l’OCDE retient : le contexte, les données d’entrées, les modèles eux-mêmes et les tâches demandées qui engendrent les sorties de l’IA), toutes les politiques publiques de régulation de ces technologies devraient prendre en compte la complexité de la chaîne de valeur de l’IA ou cette multidimensionnalité lors de la définition et de la mise en oeuvre de règles relatives à l’IA. Les dimensions en jeu aux stades de la conception, de l’entraînement, des réglages ou encore de l’utilisation des modèles d’intelligence artificielle sont autant d’objets qui justifient une prise en compte spécifique par la régulation.
4. Annoncer un programme européen de coopération en IA, associant plusieurs pays dont au moins la France, l’Allemagne, les Pays-Bas, l’Italie et l’Espagne
Il faut profiter du sommet pour annoncer le lancement d’un grand programme européen de coopération en IA. Une telle démarche, envisagée depuis 2017, n’a toujours pas connu de traductions concrètes. Cette initiative n’a pas nécessairement à réunir l’ensemble des 27 États membres, mais au moins la France, l’Allemagne, les Pays-Bas, l’Italie et l’Espagne.
Ces pays partagent une vision assez proche de l’IA et de ses enjeux, y compris l’adoption de l’IA dans le monde du travail et les objectifs d’aide aux PME et aux start-up. Il y a déjà eu des discussions sur l’IA entre la France et l’Allemagne ou entre la France et l’Italie, mais il reste à construire un programme de coopération marquant l’existence d’une voie européenne de l’IA spécifique allant plus loin que le soutien à l’innovation ou la régulation prévue par l’AI Act, une approche basée sur l’éthique et la prise en compte des conséquences à court, moyen et long termes de ces technologies.
Pour les rapporteurs, l’IA ouvre un espace d’opportunités qui peut nous aider à aller vers des sociétés solidaires soucieuses d’usages des technologies conformes aux droits de l’homme et aux valeurs humanistes. C’est un choix politique qui permettra d’éviter les seuls usages capitalistes, sécuritaires et oppressifs de ces technologies.
5. Associer le Parlement à l’organisation du sommet
Afin de garantir une plus grande légitimité du futur sommet, il est nécessaire d’associer plus étroitement le Parlement à son organisation.
La nomination d’un sénateur et d’un député au sein du comité de pilotage du sommet serait à cet égard un gage important de crédibilité, marquant la volonté de l’exécutif d’accroître le fondement démocratique de la réflexion française sur l’encadrement de l’IA à l’échelle internationale.
6. Développer une filière française ou européenne autonome sur l’ensemble de la chaîne de valeur de l’intelligence artificielle
La première de nos propositions au niveau national est un objectif qui doit tous nous mobiliser, pouvoirs publics nationaux et locaux, décideurs économiques, associations et syndicats : nous devons viser le développement d’une filière française ou européenne autonome sur l’ensemble de la chaîne de valeur de l’intelligence artificielle, même sans chercher à rivaliser avec les puissances américaines et chinoises en la matière. En effet, mieux vaut une bonne IA chez soi qu’une très bonne IA chez les autres. Il s’agit de se protéger par la maîtrise de l’ensemble des couches de la technologie.
Que ce soit au niveau européen, par l’UE ou avec une coopération renforcée entre quelques pays, ou directement au niveau national, la France doit relever ce défi de construire pour elle, en toute indépendance, les nombreux maillons de la chaîne de valeur de l’intelligence artificielle. L’enjeu de la souveraineté nationale sur cette chaîne est crucial, c’est une condition à la fois de notre indépendance en général et d’une véritable autonomie stratégique sur ces technologies d’IA. Lorsqu’une maîtrise complète de la chaîne ne sera pas possible, notre pays pourra se tourner vers ses partenaires européens pour construire les coopérations nécessaires.
Un article récent de dirigeants de Mc Kinsey, publié le 31 octobre 2024 dans Les Échos se prononce également en faveur « d’une stratégie holistique pour couvrir l’ensemble de la chaîne de valeur de la technologie » en Europe, de l’énergie jusqu’aux applications en passant par les semi-conducteurs, les infrastructures et les modèles. L’Europe est aujourd’hui leader dans un seul des segments de la chaîne de valeur de l’IA, celui très précis de la gravure des puces, et ce grâce à ASML. Cet article, sans y faire référence explicitement, repose sur le constat dressé dans une note du Mc Kinsey Global Institute d’octobre 2024 analysant la place des pays européens dans chacun des maillons de la chaîne de valeur de l’IA.
En dehors de la niche très spécifique d’ASML, les entreprises européennes restent dans la course en matière de conceptions des modèles, d’applications d’IA et de services mais elles ne représentent que moins de 5 % de parts de marché pour les matières premières (silicium en particulier), la conception des processeurs, la fabrication des puces, les infrastructures de calcul en nuage et les supercalculateurs. Ces filières sont à développer.
Outre l’augmentation des investissements, par exemple à travers les marchés publics, comme pour des applications d’IA dans les secteurs de la défense ou de la santé par exemple, Mc Kinsey invite à prendre pleinement position sur le marché des semi-conducteurs (via des technologies émergentes notamment), à lutter contre la fuite des cerveaux en assurant l’attraction des talents, et à former davantage aux métiers des différentes filières de l’IA, par des programmes de requalification de la main-d’oeuvre pour la préparer à ces nouveaux défis.
Les rapporteurs ont retenu de leurs comparaisons internationales qu’il faut commencer à lutter réellement contre la fuite des cerveaux. L’Inde et la Chine ont toutes deux compris l’importance pour leurs stratégies nationales en IA de retenir leurs talents et d’inciter au retour de leurs expatriés. En créant des écosystèmes compétitifs favorables à l’innovation, en offrant des opportunités de carrière attractives, en renforçant le sentiment national et surtout à travers divers dispositifs concrets, la France pourra suivre la voie ouverte par ces deux pays et limiter voire inverser la tendance à la fuite des cerveaux. Nous devons aller dans cette direction. Notre pays n’est pas un centre de formation destiné à préparer les futurs génies de la Silicon Valley.
7. Mettre en place une politique publique de l’IA avec des objectifs, des moyens et des outils de suivi et d’évaluation
Plutôt que d’annoncer une stratégie sans objectifs, sans gouvernance et sans outils de suivi, visant pourtant à « faire de la France un leader mondial de l’IA », il convient de mettre en place une véritable politique publique de l’IA avec des objectifs, des moyens réels dont une gouvernance digne de ce nom, et, enfin, des outils de suivi et d’évaluation. Ces éléments sont aujourd’hui cruellement absents des politiques publiques menées en France en matière d’intelligence artificielle.
Plus largement, la politique de la Start-up Nation avec son bras armé la French Tech, aussi élitiste qu’inadaptée, est à abandonner au profit d’une politique de souveraineté numérique, cherchant à construire notre autonomie stratégique et à mailler les territoires.
8. Organiser le pilotage stratégique de la politique publique de l’intelligence artificielle au plus haut niveau
La stratégie nationale pour l’IA ne dispose pas d’une gouvernance digne de ce nom et, comme l’ont montré les développements du présent rapport, le coordinateur national à l’intelligence artificielle ne représente qu’une toute petite équipe rattachée à un service de Bercy, la DGE. Il faudra, au moins, mieux coordonner la politique publique nationale de l’intelligence artificielle que nous appelons de nos voeux et lui donner une réelle dimension interministérielle avec un rattachement du coordinateur au Premier ministre.
La nomination d’une secrétaire d’État à l’intelligence artificielle et au numérique va dans le bon sens, mais il faut aller plus loin que ce premier pas symbolique et définir un pilotage stratégique de la politique publique de l’intelligence artificielle au plus haut niveau avec une coordination interministérielle.
9. Former les élèves de l’école à l’Université, former les actifs et former le grand public à l’IA
Il est indispensable de lancer de grands programmes de formation à destination des scolaires, des collégiens, des lycéens, des étudiants, des actifs et du grand public à l’IA. De ce point de vue, les politiques conduites par la Finlande, qui ont été présentées de manière détaillée, sont des modèles à suivre. La démystification de l’IA est une première étape importante et nécessaire pour permettre une adhésion à son développement. Elle favorisera aussi la diffusion de la technologie dans la société et dans nos entreprises. Et des programmes de formation de haut niveau permettront par ailleurs une montée en compétence en IA en France, qui dispose déjà d’atouts importants en la matière.
Il faut aussi promouvoir une vision scientifiquement éclairée et plutôt optimiste de l’intelligence artificielle, telle que celle portée par Yann LeCun par exemple, qui est l’un de nos plus grands experts de ces technologies. L’IA générale reste pour l’heure une perspective peu probable et la question des risques existentiels éventuellement posés par ces technologies n’est pas une priorité, même si elle fait écho aux représentations catastrophistes que le grand public se fait souvent de l’IA en lien avec les récits de science-fiction et le cinéma. Les rapporteurs, comme leurs prédécesseurs de 2017, jugent indispensable de démystifier l’intelligence artificielle.
10. Accompagner le déploiement de ces technologies dans le monde du travail et la société, notamment par la formation permanente
S’il est difficile de prévoir l’impact précis que l’IA aura sur le marché du travail, comme l’ont montré les développements à ce sujet dans le présent rapport, il faut tout de même accompagner le déploiement de ces technologies, notamment l’IA générative, dans le monde du travail, en particulier par des programmes de formation permanente ambitieux.
LaborIA s’intéresse aux aspects qualitatifs de ces transformations, mais il ne faut pas oublier les enjeux quantitatifs. C’est pourquoi il est recommandé de mener régulièrement des études qualitatives et quantitatives sur l’impact de l’IA sur l’emploi, le tissu social (dont les inégalités) et les structures cognitives en vue d’éclairer les pouvoirs publics et d’anticiper les mutations des pratiques professionnelles et les changements structurels dans les secteurs d’activité. Sur cette base, il sera possible d’ajuster plus efficacement les programmes de formation permanente et d’adapter les politiques publiques, par exemple en matière d’éducation, de recherche ou de soutien à l’innovation.
11. Lancer un grand dialogue social autour de l’intelligence artificielle et de ses enjeux
Le dialogue social par la négociation collective peut être renouvelé par l’introduction de cycles de discussions tripartites autour de l’IA et de ses nombreuses problématiques. Une opération d’envergure nationale, comme un Grenelle de l’IA, pourrait également être organisée.
Le dialogue social autour de l’IA devrait aussi se décliner dans les entreprises avec les salariés, les responsables des systèmes d’information et les DRH pour permettre une meilleure diffusion des outils technologiques et un rapport moins passionné à leurs conséquences. Comme le présent rapport l’a montré, c’est en effet une occasion de favoriser l’appropriation concrète et réaliste de la technologie et de ses enjeux, en se débarrassant des mythes entourant l’IA.
12. Mobiliser et animer l’écosystème français de l’IA
L’écosystème français de l’IA ne doit pas être mobilisé qu’à travers la French Tech, des meet-up à Station F et l’événement annuel VivaTech. Tous les acteurs de l’IA, la recherche publique et privée, les grands déployeurs de systèmes mais aussi l’ensemble des filières économiques via des correspondants IA (qui pourraient être des représentants des DSI par secteur) doivent pouvoir faire l’objet d’une grande mobilisation générale.
C’est un peu l’esprit qui avait régné entre décembre 2016 et mars 2017 lors de la préparation du plan France IA voulu par le Président de la République, alors François Hollande, un plan sans doute trop rapidement enterré au profit d’une stratégie de Start-up Nation dont les impasses et les lacunes apparaissent de plus en plus nettement avec le temps.
Il y manquait tout de même une structure d’animation, raison pour laquelle les rapporteurs suggèrent de mobiliser l’écosystème français de l’IA autour de pôles d’animation régionaux, en relation étroite avec les universités, les centres de recherche, comme Inria, et les entreprises. Des expériences étrangères ayant concrétisé l’approche initiale de France IA peuvent nous inspirer. La structure NL AI Coalition, créée par le gouvernement néerlandais et rencontrée par les rapporteurs à La Haye, rassemble ainsi depuis cinq ans l’écosystème public et privé de l’IA aux Pays-Bas, avec le concours du patronat, des universités et des grands centres de recherche. Elle s’appuie sur sept centres régionaux et est organisée en 18 groupes de travail thématiques.
13. Reconduire le programme « Confiance.ai » ou mettre en place un projet équivalent
Le programme « Confiance.ai » s’est interrompu en 202.4 alors qu’il ne coûtait pas cher et était efficace Il visait à permettre aux industriels d’intégrer des systèmes d’IA de confiance dans leurs process grâce à des méthodes et des outils intégrables dans tout projet d’ingénierie.
Pour ce faire, le programme levait les verrous associés à l’industrialisation de l’IA comme la construction de composants de confiance maîtrisés, la construction de données et/ou de connaissances pour augmenter la confiance dans l’apprentissage ou encore l’interaction générant de la confiance entre l’utilisateur et le système fondé lui-même sur l’IA de confiance. Il réunissait dans une logique partenariale de grands acteurs académiques et industriels français dans les domaines critiques de l’énergie, la défense, des transports et de l’industrie 4.0 comme l’illustre ce graphique.
Les partenaires du programme Confiance.ai
Le programme visait la construction d’une plateforme sûre, fiable et sécurisée d’outils logiciels, qui soit à la fois souveraine, ouverte, interopérable et pérenne dans les secteurs des produits et services critiques les plus concernés, mutualisant les savoir-faire scientifiques et technologiques et contribuant au cadre technique du règlement européen sur l’intelligence artificielle. Dans ce contexte, il est demandé au gouvernement et, en particulier, à la DGE de reconduire le programme « Confiance.ai » ou de mettre très rapidement en place un projet équivalent capable d’allier des expertises en termes de technologie, d’évaluation et de normalisation de l’intelligence artificielle.
Son coût d’environ 3,75 millions d’euros par an est à mettre en regard des 37 milliards d’euros de dépenses proposés par la commission sur l’intelligence artificielle en 2024. Le programme « Confiance.ai » n’en représentait que 1 %, or au vu de ses actions et de ses résultats, il justifie la poursuite d’un effort budgétaire raisonnable et pourtant rentable.
14. Soutenir la recherche publique en intelligence artificielle selon des critères de transversalité et de diversification des technologies
La recherche privée en intelligence artificielle a pris beaucoup d’avance sur la recherche publique, mais cette dernière doit revenir dans la course. La soutenir davantage est un impératif. L’Office juge pertinent de l’orienter vers des activités transdisciplinaires et, plus globalement, transversales autour de « projets de recherche » en IA.
La préoccupation à l’égard de la diversification des technologies est aussi fondamentale : les avancées en IA se font par la combinaison et la recomposition de savoirs et de savoir-faire, pas par l’enfermement dans un modèle unique que l’on chercherait à perfectionner. L’IA générative, à travers son modèle Transformer, ne doit pas devenir la priorité du monde de la recherche, en dépit de l’effet de mode autour de ChatGPT.
L’IA symbolique, par exemple, ne doit pas être totalement abandonnée, elle peut s’hybrider avec les IA connexionnistes pour forger de nouvelles approches logiques, imbriquant le signifiant et le signifié et, partant, plus proches des raisonnements humains. D’autres technologies permettant d’apporter plus de logique aux systèmes d’IA générative peuvent également inspirer de nouvelles perspectives pour la recherche, comme les modèles « Mixture of Experts » (MoE), les arbres de pensées ou Trees of Thoughts (ToT) et la génération augmentée de récupération ou Retrieval Augmented Generation (RAG).
La prise en compte de modèles de représentation du monde (« World Models ») dans de nouvelles « architectures cognitives » est un autre défi que la recherche devra relever, permettant aux IA de prendre en compte la réalité spatio-temporelle, y compris le monde physique et ses lois.
Pour paraphraser Rabelais qui écrivait que « Science sans conscience n’est que ruine de l’âme », les rapporteurs affirment que « l’IA sans logique n’est qu’illusion d’intelligence ».
15. Relever le défi de la normalisation en matière d’intelligence artificielle
Il faut permettre à la France de défendre au mieux l’intérêt national ainsi que les intérêts de nos entreprises nationales en matière de normalisation de l’IA, ce qui implique de mobiliser davantage l’Afnor et surtout le Cofrac, aujourd’hui désinvesti sur ce sujet.
Il faudrait aussi maintenir ou augmenter le financement de nos organismes de normalisation qui remplissent leurs missions dans des conditions parfois difficiles.
Enfin, la France doit inviter ses partenaires européens à faire preuve d’une plus grande vigilance dans le choix de leurs représentants dans les comités chargés de la normalisation en IA : s’appuyer sur des experts issus d’entreprises extra-européennes, le plus souvent américaines ou chinoises, n’est pas acceptable.
16. S’assurer du contrôle souverain des données issues de la culture française et des cultures francophones et créer des jeux de données autour des cultures francophones
Il faut à la fois s’assurer du contrôle souverain des données issues de la culture française, notamment des archives détenues par la BNF ou l’Institut national de l’audiovisuel, voire des cultures francophones et créer des datasets autour des cultures francophones, en vue d’alimenter l’entraînement de modèles d’IA reflétant notre environnement linguistique et culturel.
Il s’agit d’un acte de résistance face à la domination linguistique et culturelle anglo-saxonne, en particulier américaine, qui caractérise l’IA aujourd’hui et qui fait courir un risque grave d’uniformisation culturelle et d’appauvrissement linguistique. Les jeux de données autour des cultures francophones pourront être constitués avec le concours de tous les pays de la francophonie.
Les initiatives conduites par certains pays, en particulier par l’Espagne, peuvent contribuer à inspirer notre pays et à aider à la définition du cadre de ces datasets. En effet, le gouvernement espagnol a lancé depuis 2022 un plan national autour de la « nouvelle économie de la langue ». Il vise à placer l’espagnol au coeur de la transformation numérique et de la promotion de la chaîne de valeur de la nouvelle économie de la connaissance et de l’intelligence artificielle.
La France doit faire la même chose pour le français. Ainsi, le plan de l’Espagne se décline notamment en constitution de bases de données textuelles dans les langues espagnoles, ces datasets, permettant l’entraînement de modèles et la création de LLM basés sur la langue et la culture espagnoles.
Comme l’Espagne, qui a réservé une part de son plan à ses langues « co-officielles » (catalan, basque, galicien) à côté de l’espagnol, la France pourrait avantageusement consacrer une part de ces jeux de données autour des cultures francophones aux langues régionales (breton, occitan, basque, corse, langues pratiquées dans les territoires ultramarins…) dont l’appartenance au patrimoine national a été consacrée par la Constitution depuis 2008.
17. Préparer une réforme des droits de propriété intellectuelle dont le droit d’auteur pour les adapter aux usages de l’IA générative
Il faut poser les bases d’une réforme des droits de propriété intellectuelle et du droit d’auteur pour les adapter aux usages de l’IA générative et aux problèmes posés plus généralement par l’utilisation de l’intelligence artificielle.
Notre législation en matière de propriété intellectuelle et de droits d’auteur applicables à l’IA générative nécessite à l’évidence plusieurs éclaircissements. Le rapport d’information de la commission des lois de l’Assemblée nationale déposé en conclusion des travaux de sa mission d’information sur les défis de l’intelligence artificielle générative en matière de protection des données personnelles et d’utilisation du contenu généré s’est consacré à ce travail de clarification.
L’objectif d’une telle réforme sera à la fois de clarifier les régimes juridiques applicables, de protéger les ayants droit des données ayant servi à l’entraînement des modèles mais aussi les créateurs d’oeuvres nouvelles grâce à l’IA.
Cela impliquera donc, d’une part, de trancher l’épineuse question de l’équilibre entre les intérêts des ayants droit et intérêt des entreprises développant des modèles d’intelligence artificielle, d’autre part, de lever le doute sur la frontière entre oeuvre originale et contrefaçon ou copie dans le cas d’un travail créé par IA puisque la réforme devra aussi mettre fin au flou juridique entourant le statut des oeuvres créées par l’intelligence artificielle.
La solution des droits voisins, utilisée dans les secteurs de la musique et du cinéma, mais aussi de l’information (dont la presse écrite) à la suite des transformations liées au numérique et à Internet, est une perspective dont il faut débattre.
Face au succès des plateformes de streaming et de service de vidéo à la demande, l’enjeu de ces compensations financières devient grandissant. Il le sera encore plus avec la diffusion de l’IA. L’UE s’est d’ailleurs dotée en 2019 d’une directive sur le droit d’auteur et les droits voisins dans le marché unique numérique, qu’il faudra faire évoluer au rythme des capacités de création de l’IA.
Techniquement, l’utilisation de données propriétaires et surtout de contenus protégés par le droit d’auteur peut non seulement être limitée en amont par le nettoyage des données mais dorénavant corrigée en aval grâce à une nouvelle technologie introduite récemment appelée Model disgorgement ou Machine Unlearning.
Les entreprises qui collecteraient illégalement des données pour les utiliser à fin d’entraînement de leurs modèles pourraient par exemple être dans l’obligation non seulement de supprimer les données problématiques et de les abandonner lors de futurs entraînements mais surtout de mettre à jour leurs modèles en faisant comme si ces données n’avaient jamais été utilisées. Plutôt que de réentraîner totalement leurs modèles, les entreprises s’appuieraient alors utilement sur cette technique émergente qui pourra encore être perfectionnée.
18. Confier à l’OPECST le suivi et l’évaluation régulière de la politique publique conduite par le Gouvernement en la matière
La politique nationale en matière d’IA conduite par le Gouvernement devrait faire l’objet d’un suivi et d’une évaluation régulière par l’OPECST. Les aspects scientifiques et technologiques de l’intelligence artificielle ainsi que les enjeux qu’ils soulèvent appellent une expertise et une vigilance à la croisée des mondes politiques et scientifiques, c’est donc logiquement à l’OPECST qu’il convient de faire appel.
Dans le rapport précité de la commission des lois de l’Assemblée nationale, nos collègues députés – ayant constaté que le premier travail parlementaire relatif à l’IA avait été fait dans le rapport de l’OPECST de mars 2017 « Pour une intelligence artificielle maîtrisée, utile et démystifiée », qualifié « d’étude approfondie » – préconisent dans leur 33e recommandation de confier à l’OPECST un suivi permanent des questions relatives à l’intelligence artificielle.
LA GOUVERNANCE EUROPÉENNE DE L’INTELLIGENCE ARTIFICIELLE
Les réflexions menées au sein de l’UE en termes de régulation de l’IA depuis quatre ans sont très proches de celles conduites par l’OCDE. Mais l’encadrement européen des systèmes d’IA ne se limite pas au régime spécifique les concernant. Le droit de l’Union européenne prévoit en effet différentes dispositions concernant les outils numériques qui peuvent impacter les systèmes d’intelligence artificielle. Depuis le 13 juin 2024, un règlement est totalement consacré à l’encadrement de l’IA ; il s’ajoute à de nombreuses autres dispositions.
Les textes sont très nombreux, parfois d’application sectorielle, il est donc difficile de tous les récapituler ici. Pour mémoire, les plus récents et les plus transversaux viennent compléter le règlement général sur la protection des données (RGPD) du 27 avril 2016 et s’insèrent dans la « Stratégie numérique pour l’Europe pour la décennie 2020-2030 » : à l’instar du règlement sur les marchés numériques du 14 septembre 2022 (dit « DMA », pour Digital Markets Act, empêchant notamment les géants du numérique de privilégier leurs services sur leurs plateformes en laissant chacun choisir librement son moteur de recherche, son navigateur ou sa messagerie) ; du règlement sur les services numériques du 19 octobre 2022 (dit « DSA », pour Digital Services Act, qui responsabilise les plateformes en rendant illégal en ligne ce qui est illégal hors ligne, comme les contenus illicites, et dont l’esprit se retrouve dans la loi du 21 mai 2024 visant à sécuriser et à réguler l’espace numérique (dite loi « SREN ») en interdisant – en ligne – les arnaques, la haine, la désinformation et la publicité ciblée sur les mineurs ou encore en protégeant les mineurs de la pornographie ; du règlement sur la gouvernance des données du 30 mai 2022 ; du règlement sur la cybersécurité du 17 avril 2019, de la directive sur la cybersécurité du 14 décembre 2022 et du règlement sur la cybersécurité du 13 décembre 2023 ; du règlement du 12 mars 2024 sur la cyberrésilience, etc.
Dans ce contexte foisonnant, il est important de noter qu’en 2024, au terme de plusieurs années de travail préparatoire, un cadre visant spécifiquement les systèmes d’intelligence artificielle a été adopté à travers le règlement du 13 juin 2024 établissant des règles harmonisées concernant l’intelligence artificielle, communément dénommé AI Act. Il fait l’objet d’une application progressive d’ici à 2026 avec des règles harmonisées applicables à la mise sur le marché, à la mise en service et à l’utilisation de systèmes d’IA.
Présenté par l’Union européenne comme « premier texte législatif de ce type au monde », cette réglementation, qui se veut pionnière, a donc vocation à devenir un standard mondial concernant la mise sur le marché, la mise en service et l’utilisation de ces systèmes dans le but de garantir que l’IA soit une technologie « axée sur l’humain » et que les systèmes d’IA soient « sûrs, éthiques et dignes de confiance ».
Comme l’assure l’exposé des motifs du projet de règlement, l’AI Act vient compléter le droit de l’Union et ne le remplace pas, en particulier en ce qui concerne les droits fondamentaux ; la protection de la vie privée, des données, des consommateurs et des travailleurs ; l’emploi ; la sécurité des produits. Les droits et les recours existants pour les personnes sur lesquelles les systèmes d’IA sont susceptibles d’avoir des incidences négatives demeurent inchangés et pleinement applicables. L’intelligence artificielle ne suspend pas le droit en vigueur.
1. Le travail préparatoire conduit par les institutions européennes entre 2018 et 2020
La construction des bases de la gouvernance européenne en matière d’intelligence artificielle s’est d’abord appuyée sur trois principales contributions : une communication de la Commission européenne en avril 2018, les différentes recommandations d’un groupe d’experts placé auprès de la Commission européenne en 2019 puis un Livre blanc de la Commission en 2020.
a) La communication de la Commission européenne d’avril 2018
La Commission européenne a tout d’abord publié en avril 2018 une communication pour l’intelligence artificielle en Europe. Elle appelait à la mise en place d’un cadre éthique et juridique conforme aux valeurs de l’Union européenne et à la Charte des droits fondamentaux, mais sans préconiser la création d’une législation contraignante spécifique à l’intelligence artificielle. Au lieu de cela, la communication attirait l’attention sur les cadres juridiques existants (la protection des données personnelles avec le RGPD de 2016, les règles relatives à la sécurité des produits et les régimes de responsabilité civile ordinaires).
Sur la base de cette première communication, un travail de coordination a été conduit avec les États membres et la Norvège en vue d’aboutir rapidement à un plan coordonné pour l’IA en Europe. Le 7 décembre 2018, la Commission européenne a publié une communication sur les objectifs et les initiatives d’un plan coordonné dans le domaine de l’intelligence artificielle, plan actualisé en 2021.
b) Le groupe d’experts de haut niveau sur l’IA
Dans la perspective de ses futurs travaux sur l’IA, la Commission européenne avait entretemps nommé en juin 2018 un groupe d’experts de haut niveau sur l’IA (high-level experts group on artificial intelligence ou HLEG AI en anglais).
Ce groupe était composé d’experts des milieux industriels et scientifiques et présidé par Pekka Ala-Pietilä, président du conseil d’administration de Huhtamaki, Sanoma et Netcompany et ex-président de Nokia ainsi que docteur honoraire en technologie à l’université de Tampere en Finlande. Le groupe devait élaborer des conclusions permettant de guider l’action de la Commission ainsi que des colégislateurs en matière d’IA. Pour ce faire, il a d’abord publié en décembre 2018 une définition de la notion d’IA, qui lui a permis de circonscrire le périmètre de ses travaux.
Cette définition reprend et étend la définition de la précédente communication de la Commission :
« L’intelligence artificielle (IA) désigne les systèmes qui font preuve d’un comportement intelligent en analysant leur environnement et en prenant des mesures – avec un certain degré d’autonomie – pour atteindre des objectifs spécifiques. Les systèmes dotés d’IA peuvent être purement logiciels, agissant dans le monde virtuel (assistants vocaux, logiciels d’analyse d’images, moteurs de recherche ou systèmes de reconnaissance vocale et faciale, par exemple) mais l’IA peut aussi être intégrée dans des dispositifs matériels (robots évolués, voitures autonomes, drones ou applications de l’internet des objets, par exemple). »
Sur la base de cette définition, le HLEG AI a mis au point plusieurs livrables thématiques pour permettre à la Commission européenne de travailler sur la base de définitions et d’objectifs clairement établis.
Le premier livrable, publié en avril 2019, fixe les lignes directrices en matière d’éthique de l’IA qui permettraient d’arriver à une « IA digne de confiance ». Le groupe considère que pour qu’une technologie d’IA soit considérée comme « digne de confiance », il lui faut réunir au moins trois de ces éléments :
– être licite (respecter les législations et réglementations existantes) ;
– être éthique, et assurer l’adhésion à des principes et valeurs éthiques ;
– être équitable, diverse et non discriminatoire ;
– être transparente ;
– permettre un contrôle humain ;
– être robuste techniquement et socialement et sécurisée ;
– être robuste pour ne pas causer de préjudices involontaires ;
– respecter la vie privée et la gouvernance des données ;
– participer au bien-être social et environnemental ;
– savoir qui est responsable sur toute la chaîne de valeur.
Ces exigences sont proches de celles préconisées par l’OCDE pour la mise en place d’une IA éthique.
Le second livrable du HLEG AI est une liste de recommandations en matière de politiques publiques et d’investissements, avec le même objectif de garantir une « IA de confiance ». Le document formule 33 recommandations pour orienter l’IA vers la durabilité, la croissance, la compétitivité et l’action.
Les investissements doivent s’appuyer sur quatre bases : le secteur privé, le secteur public, la société civile et la recherche. Le groupe identifie huit leviers que les pouvoirs publics peuvent utiliser pour développer le potentiel de l’IA : l’éducation et la formation, la gouvernance et la régulation, le financement et l’investissement, le secteur privé, la société civile, le secteur public, la recherche ainsi que les données et l’infrastructure.
Ce document fait apparaître l’approche pluridisciplinaire que retient l’Union européenne : plutôt que de réguler un secteur en particulier, le HLEG AI estime que l’investissement doit être transversal et intégré.
Après la publication de ces deux premiers livrables, le groupe a mis en place un outil pratique d’évaluation qui permet de traduire les lignes directrices en techniques d’autoévaluation.
Enfin, le HLEG AI a réalisé un dernier livrable concernant une approche sectorielle de politiques publiques et d’investissement pour l’IA.
Ce dernier livrable était particulièrement destiné à l’Alliance européenne pour l’IA (European AI Alliance), une coalition créée par la Commission européenne en 2018 dans le but « d’ouvrir le dialogue sur l’intelligence artificielle ». Cette alliance est composée de 6 000 parties prenantes de la société civile européenne (citoyens, représentants des consommateurs et des entreprises, syndicats, établissements de recherche, autorités et experts).
Après la publication de ce dernier livrable, le mandat de l’AI HLEG est arrivé à son terme en juillet 2020 et seule l’Alliance a continué ses activités.
c) Le Livre blanc de la Commission européenne sur l’IA
La phase de consultation des experts et de la société civile organisée par les institutions européennes a été conclue par la publication par la Commission européenne d’un Livre blanc sur l’IA de 30 pages sous-titré « Une approche européenne axée sur l’excellence et la confiance » en février 2020. Il a été soumis à consultation publique jusqu’au 19 mai 2020 et discuté lors de la deuxième assemblée de l’Alliance européenne pour l’IA en octobre 2020.
Ce rapport souligne les bénéfices apportés par l’IA, mais aussi les risques de ces technologies. Il appelle donc à un cadre juridique spécifique pour l’IA en Europe, en vue de créer un « écosystème de confiance » unique en son genre, garantissant le respect des principes du droit de l’UE, notamment ceux qui protègent les droits fondamentaux et les droits des consommateurs, en particulier vis-à-vis des systèmes d’IA à haut risque.
Avec ce cadre juridique, qui vise aussi à harmoniser les efforts aux niveaux européen, national et régional, par un partenariat entre les secteurs privé et public, l’UE pourra construire un « écosystème d’excellence » tout au long de la chaîne de valeur de l’IA.
Le livre blanc mentionne aussi quelques futures obligations pour les structures développant des systèmes d’IA à haut risque : s’assurer que les jeux de données limitent les risques et évitent les discriminations ; documenter les données utilisées pour entraîner les algorithmes, dont les techniques et méthodologies de conception et d’entraînement ; développer des systèmes robustes dès le stade de la conception puis pendant leur cycle de vie ; une supervision humaine permettant une intervention en temps réel et laissant la possibilité de désactiver le système.
Le Comité économique et social européen (CESE) a rendu un rapport sur ce livre blanc, dont la rapporteure était Catelijne Muller, membre du Comité mais aussi présidente de l’ONG ALL AI et membre de l’AI HLEG de la Commission européenne. Il regrettait la focalisation du document sur la seule intelligence artificielle axée sur les données (l’IA connexionniste) et réclamait une nouvelle génération de systèmes d’IA fondés sur la connaissance et le raisonnement.
Le CESE demandait notamment, outre un renforcement des investissements, une pluridisciplinarité dans la recherche, une approche socio-technique des technologies, une association de toutes les parties prenantes à la discussion et une éducation du grand public.
2. De la proposition de règlement du 21 avril 2021 à la juxtaposition de deux dispositifs à la suite des amendements adoptés
La législation européenne sur l’intelligence artificielle (ou AI Act) a pour origine une proposition de règlement du Parlement européen et du Conseil transmis par la Commission européenne le 21 avril 2021. Après un dialogue entre les deux législateurs de l’Union et la Commission (appelé trilogue), un consensus autour d’un texte est trouvé le 9 décembre 2023.
Ce compromis est adopté par le Parlement européen le 13 mars 2024, puis par le Conseil de l’Union européenne le 21 mai 2024. Ce projet est devenu le règlement du 13 juin 2024 établissant des règles harmonisées concernant l’intelligence artificielle.
Une évolution importante doit être notée entre le texte initial et la version finale du règlement à la suite des amendements adoptés lors de la discussion du projet de la Commission européenne par le Conseil et le Parlement européen. Le dialogue entre les institutions européennes est un processus habituel au sein du processus législatif de l’Union européenne où des compromis doivent être trouvés pour obtenir une position acceptable par la Commission, le Conseil et le Parlement.
Toutefois, le dialogue entre les institutions européennes a dans ce cas précis mené à un texte final assez différent du texte initialement proposé par la Commission européenne. Alors que le premier texte visait une régulation de l’IA orientée vers les usages de la technologie plutôt que vers la technologie elle-même, selon des niveaux de risques, le Conseil et le Parlement européen ont ajouté des dispositions différentes de cette approche initiale : en effet, il a été décidé que certains « modèles à usage général », en l’occurrence surtout les modèles de fondation les plus puissants, fassent l’objet d’un encadrement plus strict par l’AI Act, parfois du simple fait de la puissance de calcul nécessaire à l’entraînement du modèle.
Ainsi, il est possible de séparer au sein des dispositions du texte final les dispositions initialement prévues par la Commission européenne et les ajouts du Parlement européen et du Conseil.
a) Le volet issu du projet initial d’AI Act en 2021 : une régulation des usages selon leurs risques plutôt qu’une régulation de la technologie elle-même
La première partie du texte présente le projet initial de règlement, à savoir une régulation de l’IA basée sur le niveau de risque engendré par son utilisation et non par la technologie elle-même. Ainsi, la technologie n’est pas considérée comme dangereuse ou risquée en elle-même, mais pourrait l’être dans certains contextes d’utilisation. Les obligations pèsent sur les fournisseurs, les déployeurs, les fabricants et les mandataires de fournisseurs de systèmes d’IA.
L’article 5 liste un certain nombre de pratiques totalement interdites en matière d’intelligence artificielle car estimées causer un « risque inacceptable ». Il s’agit notamment de l’évaluation des personnes physiques associée à un système de crédit social ou social ranking, de la reconnaissance faciale, ou encore de la reconnaissance des émotions sur le lieu de travail.
Pour les autres usages des systèmes d’IA, il existe une gradation du niveau de risque lié à leur utilisation, qui implique des règles plus contraignantes à mesure que le niveau de risque augmente.
Les usages licites présentant niveau de « risque élevé » font l’objet des dispositions les plus rigoureuses et sont décrits à l’article 6 du texte. Il s’agit des IA utilisées dans les domaines de biométrie, d’infrastructures critiques, d’éducation et formation professionnelle, d’emploi, de gestion des travailleurs et d’accès à l’emploi indépendant, d’accès et jouissance de services privés essentiels et de services et prestations publiques essentiels, des services répressifs, de gestion de la migration, de l’asile et des contrôles aux frontières ainsi que d’administration de la justice et de processus démocratiques. L’article 7 du règlement donne le droit à la Commission de modifier la liste de ces critères.
Les systèmes d’IA dont les usages ne présentent qu’un « risque limité » sont soumis à des obligations de transparence plus légères : les développeurs et les déployeurs doivent s’assurer que les utilisateurs finaux sont conscients qu’ils interagissent avec une IA (article 50)
Il est intéressant de noter que le centre de recherche sur les modèles de fondation (Center for Research on Foundation Models ou CRFM) de l’Université de Stanford a publié une analyse évaluant la conformité des différents modèles de fondation existants avec ce premier volet du projet de règlement.
b) Le volet ajouté par les co-législateurs : la régulation des modèles de fondation assortie d’un régime spécifique pour les modèles les plus puissants, dits « à risque systémique »
Le Parlement européen a décidé d’ajouter au texte initial de la Commission une réglementation qui ne vise pas seulement les risques liés aux usages de l’IA mais la technologie et ses modèles en eux-mêmes, ce qui se rapproche de la réflexion conduite au sein de l’université de Stanford ainsi que de la réglementation américaine de 2023. Le Conseil et le Parlement européen ont ainsi introduit la notion de « modèle d’IA à usage général » (general-purpose artificial intelligence model ou GPAIM).
Cette notion est définie au point (63) de l’article 3 du texte :
« Modèle d’IA, y compris lorsqu’il est entraîné à l’aide d’une grande quantité de données en utilisant l’autosupervision à l’échelle, qui présente une grande généralité et est capable d’exécuter avec compétence un large éventail de tâches distinctes, quelle que soit la manière dont le modèle est mis sur le marché, et qui peut être intégré dans divers systèmes ou applications en aval, à l’exception des modèles d’IA utilisés pour des activités de recherche, de développement ou de prototypage avant d’être mis sur le marché ».
Dès lors qu’un modèle d’intelligence artificielle est considéré comme étant à usage général, il doit suivre les règles minimales visées à l’article 50 du règlement.
Au-delà, le régime juridique applicable dépend de son éventuelle catégorisation en « IA à usage général présentant un risque systémique ». L’article 51 prévoit en effet qu’un GPAIM est ainsi catégorisé si l’une des deux conditions suivantes est remplie :
– il a « des capacités d’impact élevées, évaluées sur la base d’outils et de méthodologies techniques appropriés, y compris des indicateurs et des critères de référence », ce qui implique pour le fournisseur du GPAIM de procéder aux évaluations nécessaires et de le notifier à la Commission ;
– sur la base d’une décision de la Commission, d’office ou à la suite d’une alerte qualifiée du groupe scientifique, il a des capacités ou un impact équivalents à ceux visés au point [précédent], compte tenu des critères énoncés à l’annexe XIII ».
Les sept critères de l’annexe XIII permettant d’évaluer l’impact des modèles d’intelligence artificielle sont les suivants :
– le nombre de paramètres du modèle ;
– la qualité et la taille des données d’entraînement ;
– la quantité de calcul utilisée pour l’apprentissage ;
– les modalités d’entrée et de sortie du modèle ;
– l’évaluation des capacités du modèle ;
– l’impact du modèle sur le marché intérieur ;
– le nombre d’utilisateurs finaux.
L’article 51 établit également une présomption d’impact élevé, donc de risque systémique, lorsque le volume cumulé de calcul utilisé pour l’apprentissage du modèle est supérieur à 1025 opérations à virgule flottante par seconde (FLOPS).
Le droit américain avec l’Executive Order de 2023 a quant à lui prévu des obligations de déclaration plus souples, avec un seuil de puissance de calcul dix fois plus grand, soit 1026.
Calculer les FLOPS utilisés pour l’entraînement d’un modèle
Le site Medium présente une heuristique pour calculer approximativement le nombre de FLOPS utilisés pour l’entraînement d’un modèle sur la base d’une publication scientifique d’OpenAI
La formule utilisée est la suivante :
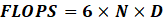
avec N correspondant au nombre de paramètres et D au nombre de tokens utilisés pour l’entraînement.
Par exemple, le modèle Llama 3 8B de Meta a huit milliards de paramètres et a été entraîné avec quinze milliards de tokens. En appliquant cette formule, une approximation du nombre de FLOPS utilisés pour l’entraînement du modèle peut faire l’objet d’un calcul :
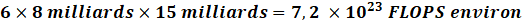
Sur la base de cette heuristique, le modèle LLama 3 8B se situe juste au-dessous du seuil et ne correspond donc apparemment pas à une IA à usage général présentant un risque systémique au sens de l’AI Act et encore moins au sens de l’Executive order américain. Pour mémoire, les modèles de pointe d’OpenAI ou de Google dépassent depuis 2023 le seuil de 1025 FLOPS, avec GPT-4 d’une part et Gemini d’autre part.
Sur la base de cette condition automatique et des sept critères permettant de juger du niveau d’impact d’un modèle, la Commission européenne peut, d’office ou à la suite d’une alerte qualifiée du groupe scientifique, faire entrer un modèle d’IA dans la catégorie des IA à usage général présentant un risque systémique.
Les modèles à usage général présentant des risques systémiques sont soumis à des obligations particulières. Ces obligations sont au nombre de quatre et sont définies à l’article 55 du règlement. Ainsi, les fournisseurs de GPAIM présentant un risque systémique doivent :
– procéder à l’évaluation du modèle conformément à des protocoles et à des outils normalisés reflétant l’état de l’art, y compris effectuer et documenter des tests contradictoires du modèle en vue d’identifier et d’atténuer les risques systémiques ;
– évaluer et atténuer les éventuels risques systémiques au niveau de l’Union, y compris leurs sources, qui peuvent résulter du développement, de la mise sur le marché ou de l’utilisation de modèles d’IA à usage général présentant un risque systémique ;
– garder trace, documenter et rapporter, sans délai injustifié, au bureau de l’IA et, le cas échéant, aux autorités nationales compétentes, les informations pertinentes concernant les incidents graves et les mesures correctives possibles pour y remédier ;
– assurer un niveau adéquat de protection de cybersécurité pour les modèles d’IA à usage général présentant un risque systémique et pour l’infrastructure physique du modèle.
Dans la pratique, ces obligations seront assurées par l’élaboration et le respect de « codes de conduite » définis à l’article 56 du règlement. Le respect de ces obligations sera également assuré par des normes auxquelles les fournisseurs d’IA présentant des risques systémiques devront se conformer.
Les critiques concernant l’AI Act portent principalement sur cette seconde partie du texte relative aux IA à usage général, qui a provoqué un blocage de la part de la France et de l’Allemagne.
En effet, la France et l’Allemagne, qui accueillent des entreprises créant des modèles de fondation comme MistralAI en France ou Aleph Alpha en Allemagne, craignaient que cette nouvelle portée de la réglementation freine l’innovation et donc la compétitivité de leurs entreprises.
Lors de leurs auditions, les rapporteurs ont pu remarquer que les critiques de l’AI Act se maintiennent autour de cette partie du texte. Gilles Babinet, coprésident du Conseil national du numérique (CNNum) a par exemple pointé le caractère ex ante de la réglementation, alors qu’à l’heure actuelle on prédit mal les effets des systèmes d’IA sur le marché économique. Il considère qu’une telle réglementation précoce a tendance à favoriser les « gros » acteurs américains face aux entreprises européennes naissantes. Joëlle Tolédano, coprésidente du CNNum et économiste, a rejoint l’avis de Gilles Babinet en pointant du doigt le déséquilibre entre les coûts nécessaires au respect des normes visant à réguler les modèles d’IA à risque systémique et le chiffre d’affaires des nouvelles entreprises de l’IA comme Mistral, moindre que celui des géants américains.
Yoshua Bengio a dénoncé la référence aux FLOPS utilisés pour l’entraînement du modèle comme mesure de calcul alors que les modèles deviendront de plus en plus performants, et de ce fait pourront utiliser beaucoup moins de puissance de calcul pour leur entraînement tout en parvenant à des résultats bien plus impressionnants.
Cette partie du règlement sur l’intelligence artificielle ne soulève toutefois pas que des critiques. Plusieurs personnes auditionnées ont souligné l’intérêt de soumettre les entreprises d’intelligence artificielle à des normes, y compris en termes de régulation des modèles, comme les chercheurs en informatique, IA et robotique Laurence Devillers, Serge Abiteboul ou Raja Chatila.
Florence G’sell, rencontrée à l’Université de Stanford, a résumé l’AI Act dans un graphique qui représente bien la dualité de son dispositif – une dualité non exclusive qui conduit donc à des chevauchements possibles en pratique – rendant encore plus complexe la mise en oeuvre du règlement.
Le double dispositif de l’AI Act : systèmes vs modèles d’IA
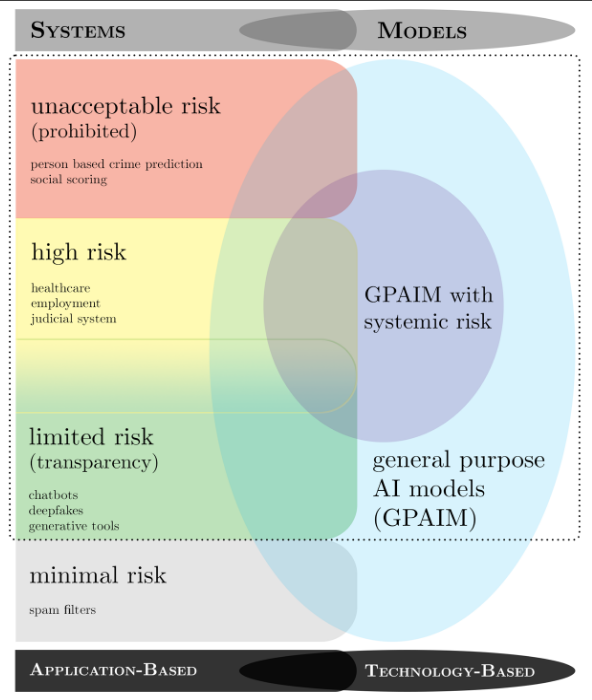
Source : Rapport de Florence G’sell, Université de Stanford, op. cit.
c) Les autres aspects de l’AI Act : une polysynodie institutionnelle, une portée extraterritoriale, un calendrier très complexe et une normalisation désinvestie
La polysynodie caractérise le dispositif institutionnel qui accompagne l’AI Act. Ce dernier confie la mise en oeuvre des diverses dispositions du règlement à plusieurs structures dont la majorité aura une fonction de conseil plutôt qu’à la seule Commission européenne, qui aurait pu s’en acquitter elle-même en s’appuyant sur sa DG Connect.
La première sera une structure exécutive, par autonomisation au sein de la Commission européenne d’une de ses directions qui devient le Bureau européen de l’IA ou EU AI Office, composé de cinq unités et de deux conseillers.
Ce nouveau centre d’expertise, dont la moitié des agents correspond à de nouveaux recrutements, a la capacité de procéder à des évaluations des modèles d’IA à usage général, de demander des informations et des mesures aux fournisseurs de modèles (y compris les codes sources des modèles et les API, mais le dialogue en amont sera privilégié) et d’appliquer le cas échéant des sanctions. La Commission européenne doit également mettre en place :
– un Conseil européen de l’IA ou European Artificial Intelligence Board, composé de représentants des États membres, qui doit conseiller la Commission européenne ainsi que le Bureau européen de l’IA et les autorités de régulation des États membres ;
– un Forum européen consultatif sur l’IA ou European Artificial Intelligence Advisory Forum qui doit conseiller le Conseil européen de l’IA, la Commission européenne et le Bureau européen de l’IA ;
– un Panel scientifique européen d’experts en IA ou European Artificial Intelligence Scientific Panel of Independent Experts qui doit conseiller le Bureau européen de l’IA spécialement sur les modèles d’IA à usage général et les risques systémiques afin de pouvoir classifier les différents modèles et systèmes d’IA. C’est lui qui aidera à définir les outils, les méthodologies et les tests pertinents. Il pourra aussi éclairer les autorités de surveillance des marchés et les autorités de régulation des États membres. Enfin, il alertera le Bureau européen de l’IA en cas de modèles d’IA à usage général à risque systémique selon la réglementation de l’UE.
S’agissant de la portée extraterritoriale du règlement, il faut souligner que l’AI Act s’applique non seulement à tout acteur qui fournit, distribue ou déploie des systèmes d’IA utilisés dans l’UE, qu’ils soient conçus dans l’UE ou dans un pays tiers, mais couvre aussi le champ des systèmes d’IA conçus et utilisés hors UE si les résultats générés par le système sont destinés à être utilisés dans l’UE.
Le calendrier de mise en oeuvre des dispositions du règlement frappe par sa très grande complexité : de 2024 à 2031, différentes étapes de déploiement de l’AI Act rythment chaque année. Parler d’usine à gaz est à cet égard un euphémisme.
Le calendrier très complexe de mise en oeuvre de l’AI Act
Le règlement du 13 juin 2024 établissant des règles harmonisées concernant l’intelligence artificielle est publié au Journal officiel de l’Union européenne le 12 juillet 2024. Il s’agit de sa notification officielle. Le 1er août 2024 est la date de son entrée en vigueur, donc de son application mais en fait, ses dispositions ne s’appliqueront que plus tard et progressivement. Le 2 novembre 2024 est la date théorique d’expiration du délai au terme duquel les États membres identifient et rendent publique la liste des autorités nationales responsables de la protection des droits fondamentaux et en informent la Commission et les autres États membres.
Les interdictions relatives à certains systèmes d’IA (prévues aux chapitres I et II) commencent à s’appliquer le 2 février 2025. Le 2 mai 2025 les codes de bonnes pratiques de la Commission doivent être prêts. Les règles relatives aux organismes notifiés (chapitre III, section 4), aux modèles d’IA à usage général (chapitre V), à la gouvernance (chapitre VII), à la confidentialité (article 78) et aux sanctions (articles 99 et 100) commencent à s’appliquer le 2 août 2025. À la même date, si le code de pratique ne peut être finalisé ou si l’AI Office le juge inadéquat, la Commission peut fournir des règles communes pour la mise en oeuvre des obligations des fournisseurs de modèles d’IA à usage général par le biais d’actes d’exécution. Toujours le 2 août 2025, les États membres désignent les autorités nationales compétentes (autorités de notification et autorités de surveillance du marché), les communiquent à la Commission et mettent leurs coordonnées à la disposition du public ; fixent les règles relatives aux sanctions et aux amendes, les notifient à la Commission et veillent à ce qu’elles soient correctement mises en oeuvre ; et font rapport à la Commission sur l’état des ressources financières et humaines des autorités nationales compétentes. Les fournisseurs de modèles d’IA à usage général mis sur le marché ou mis en service avant cette date doivent à partir du 2 août 2025 commencer à se conformer aux exigences du règlement, avec l’horizon d’une conformité d’ici le 2 août 2027.
Avant le 2 février 2026, la Commission doit fournir des lignes directrices précisant la mise en oeuvre pratique de l’article 6, y compris le plan de surveillance après la mise sur le marché. Le 2 août 2026, les autres dispositions du règlement sont applicables, à l’exception de l’article 6, paragraphe 1. Le règlement s’applique aux exploitants de systèmes d’IA à haut risque (autres que les systèmes visés à l’article 111, paragraphe 1), mis sur le marché ou mis en service avant cette date. Toutefois, il ne s’applique qu’aux systèmes dont la conception est modifiée de manière significative à partir de cette date. À la même date, les États membres veillent à ce que leurs autorités compétentes aient mis en place au moins un bac à sable réglementaire opérationnel en matière d’IA au niveau national.
Le 2 août 2027, les fournisseurs de modèles d’IA à usage général mis sur le marché avant le 2 août 2025 doivent avoir pris les mesures nécessaires pour se conformer aux obligations prévues par le règlement avant cette date. Les systèmes d’IA composants de systèmes d’information à grande échelle qui ont été mis sur le marché ou mis en service avant cette date doivent être mis en conformité avec le règlement d’ici au 31 décembre 2030.
Le 2 août 2028, la Commission évalue le fonctionnement de l’AI Office et l’impact et l’efficacité des codes de conduite volontaires (puis tous les trois ans). La Commission évalue et fait rapport au Parlement européen et au Conseil sur la nécessité de modifier les rubriques de l’annexe III, le système de supervision et de gouvernance et la liste des systèmes d’IA nécessitant des mesures de transparence supplémentaires à l’article 50. La Commission présente enfin un rapport sur l’état d’avancement des « résultats de la normalisation » qui couvrent le thème du développement économe en énergie de modèles d’IA à usage général. Ce rapport doit être soumis au Parlement européen et au Conseil, et rendu public.
Le 1er décembre 2028 (soit 9 mois avant le 1er août 2029), la Commission doit établir un rapport sur la délégation de pouvoir décrite à l’article 97.
Le 1er août 2029, le pouvoir de la Commission d’adopter les actes délégués prévus par huit articles expire, à moins que cette période ne soit prolongée : la délégation de pouvoir sera alors, par défaut, prolongée pour des périodes récurrentes de 5 ans, à moins que le Parlement européen ou le Conseil ne s’oppose à cette prolongation trois mois ou plus avant la fin de chaque période.
Le 2 août 2029 (puis tous les quatre ans), la Commission présente au Parlement européen et au Conseil un rapport sur l’évaluation et le réexamen du règlement.
Les fournisseurs et déployeurs de systèmes d’IA à haut risque destinés à être utilisés par les autorités publiques doivent avoir pris avant le 2 août 2030 les mesures nécessaires pour se conformer aux exigences et aux obligations du règlement.
Le 31 décembre 2030 est la date limite pour la mise en conformité avec le règlement des systèmes d’IA composants de systèmes d’information à grande échelle qui ont été mis sur le marché ou mis en service avant le 2 août 2027.
Enfin, le 2 août 2031, la Commission procède à une évaluation de l’application du règlement et fait rapport au Parlement européen, au Conseil et au Comité économique et social européen.
Source : d’après le site https://artificialintelligenceact.eu/fr/implementation-timeline/
Le texte du règlement donne une place importante à la normalisation technique des produits utilisant l’IA. Cette normalisation doit garantir des standards de qualité et donc d’assurer une confiance envers ces produits pour lesquels les citoyens semblent, pour l’heure, relativement méfiants. Ces dix normes harmonisées auront aussi pour rôle de vérifier si un système d’IA correspond a priori aux obligations prévues au règlement : un système qui respecte ces normes sera en effet supposé conforme à l’AI Act.
Plusieurs spécialistes entendus par les rapporteurs ont exprimé leur intérêt pour le processus de normalisation technique introduit par la seconde partie de l’AI Act. Yann Ferguson, sociologue directeur scientifique du LaborIA d’Inria ainsi que Patrick Bezombes, conseiller pour la stratégie et la gouvernance de l’IA à l’Association française de normalisation (Afnor) et représentant de la France au CEN-CENELEC ont défendu ce point de vue.
Selon eux, il faut considérer deux catégories d’entreprises : d’une part, les entreprises industrielles « classiques », Patrick Bezombes parle d’entreprises de la « safety », d’autre part, les nouvelles entreprises du numérique. Ces deux types d’entreprises ne voient pas de la même façon le développement de leurs produits. Les entreprises classiques de l’industrie comme Airbus, Alstom ou Framatome sont habituées à une normalisation stricte de leurs process de production, normalisation nécessaire dans leur propre intérêt pour garantir la sécurité essentielle de leurs produits et leur réputation. Ainsi, lorsque leurs produits arrivent sur le marché, le risque de défaillance est minime : la moindre panne d’un avion, d’un train ou d’un réacteur nucléaire serait catastrophique pour leur image et la confiance des consommateurs.
À l’inverse, les nouvelles entreprises du numérique, notamment les MAAAM, sont moins confrontées à ce type de problèmes, et s’autorisent des marges d’erreur élevées, d’autant plus qu’elles peuvent se permettre la mise sur le marché de produits présentant des défauts qui pourront être corrigés par la suite, grâce à une mise à jour logicielle. Dans ces entreprises, la culture de respect des normes est moins développée que dans les entreprises classiques, surtout celles du secteur industriel, où elle est présente dans toutes les étapes de la conception à la fabrication des produits.
De ce point de vue, le règlement sur l’intelligence artificielle peut être perçu comme un moyen d’encourager les entreprises du numérique à changer de culture et à respecter des normes strictes lorsqu’elles commercialisent un produit. Patrick Bezombes a particulièrement rappelé l’importance de ces normes qui permettent de créer de la confiance envers un produit, ce qui est essentiel pour la présence sur un marché.
Il relativise l’idée selon laquelle cette normalisation pénaliserait les petites entreprises par rapport aux géants du numérique. En effet, une défaillance majeure d’un produit sur le marché provoque une crise de la confiance sur l’ensemble du marché, tant à l’égard des grandes entreprises que des plus petites. Le cas des véhicules autonomes l’illustre. Aussi, en limitant le risque de défaillances sur les produits utilisant de l’intelligence artificielle, la normalisation permet d’éviter ces crises de confiance. La confiance générée par cette normalisation, créatrice de stabilité, bénéficie à l’ensemble des acteurs du marché.
Pour mieux comprendre comment les normes relatives à l’IA sont en train d’être définies, il faut comprendre qui est chargé de cette normalisation.
En Europe, le Comité européen de normalisation (CEN) et le Comité européen de normalisation en électronique et en électrotechnique (CENELEC) sont chargés de préparer les normes relatives à l’IA prévues par l’AI Act. Un comité commun ou Joint Technical Committee (JTC CEN-CENELEC) a été mis en place pour l’IA, le JTC 21.
Il doit produire des livrables normatifs et des lignes directrices à destination des autres comités techniques concernés par l’intelligence artificielle. Ce JTC doit également examiner l’adoption éventuelle de normes internationales pertinentes ainsi que les normes d’autres organisations compétentes, comme celles du JTC ISO-IEC 1 et ses sous-comités, tels que le SC 42.
Patrick Bezombes, responsable IA à l’Afnor représente la France au JTC 21 du CEN-CENELEC, dont il est le vice-président. L’architecture complexe des organismes de normalisation est résumée dans le tableau suivant.
Tableau des agences de normalisation dans le monde, en Europe et en France
| Normalisation des technologies de l’information | Normalisation de l’électrotechnique | Normalisation des télécommunications | Autres organisations sectorielles | |
| Monde | Joint technical committees (JTC) de l’ISO et de l’IEC. Son sous-comité 42 (SC 42) est chargé de la normalisation de l’IA | Union internationale des télécommunications (UIT ou ITU), organe chargé de la normalisation des sujets de l’IT et de la communication en réseau | Institute of Electrical and Electronics Engineers (IEEE) pour l’informatiqueSociety of Automotive Engineers (SAE) pour les voitures autonomes | |
| International organization for standardization (ISO), chargée initialement des seuls sujets d’IT mais aujourd’hui chargée d’une normalisation plus large | International Electrotechnical Commission ou Commission électrotechnique internationale (IEC ou CEI), chargée de la normalisation dans le secteur de l’électrotechnique | |||
| Europe | CEN-CENELEC Management Centre (CCMC), secrétariat commun au CEN et au CENELECJoint technical committees (JTC) dont le JTC CEN-CENELEC 21 sur l’IA | European Telecommunications Standards Institute (ETSI), miroir de l’UIT au niveau européen(marginalisé depuis la crise sur les normes du système Galileo, n’intervient pas sur la normalisation prévue par l’AI Act) | Aucun organisme reconnu officiellement par l’Union européenne | |
| Comité européen de normalisation (CEN), miroir de l’ISO au niveau européen | Comité européen de normalisation en électronique et en électrotechnique (CENELEC), miroir de l’IEC au niveau européen | |||
| France | Association française de normalisation (Afnor), représentant la France à l’ISO et au CEN-CENELEC en matière d’IA | Union technique de l’électricité (UTE)Centre technique industriel (CTI) | ||
Légende : Les cases grisées sont des instances de normalisation communes, des JTC ISO-IEC ou CEN-CENELEC
La normalisation réalisée dans le cadre du CEN-CENELEC, notamment dans le JTC 21, loin d’être purement technique, reflète aussi des choix politiques et économiques. L’implication de la France et la qualité de sa participation au processus de normalisation dépendent des acteurs qui prennent part à ce processus pour notre pays ainsi que de l’investissement des pouvoirs publics dans ce travail.
Patrick Bezombes de l’Afnor déplore par exemple que le Comité français d’accréditation (Cofrac), chargé de certifier les entreprises respectant les normes, ne s’implique pas davantage dans les discussions relatives à la normalisation prévue par l’AI Act.
Il invite également à se méfier des positions tenues par des pays qui n’ont pas fait le choix d’envoyer des représentants « indépendants » au sein du JTC, soit parce qu’ils n’ont pas d’entreprises nationales de taille importante dans le domaine de l’IA, soit parce que les entreprises étrangères, souvent américaines ou parfois chinoises, ont investi ce champ de la normalisation.
En effet, derrière la représentation des 26 autres États membres dans les comités de normalisation, Patrick Bezombes déplore qu’on retrouve souvent des représentants de grands groupes du numérique extra-européens qui défendent leurs intérêts et tentent d’influencer les discussions en faveur d’une standardisation plus légère, de moins bonne qualité et plus conforme à leurs intérêts et à leurs attentes envers l’UE.
Il a fourni aux rapporteurs une liste éclairante des liens d’intérêt qui unissent plusieurs des membres du JTC 21 du CEN-CENELEC sur la normalisation de l’intelligence artificielle à des grandes entreprises étrangères du secteur du numérique.
Au total, le chantier stratégique de la normalisation est désinvesti par les gouvernements des États membres et par la Commission européenne alors qu’il devrait être surveillé de très près par les pouvoirs publics, les administrations nationales et les institutions européennes.
3. Une gouvernance européenne de l’IA à compléter
a) Mobiliser les entreprises et élaborer de la Soft Law : l’AI Pact et les bonnes pratiques
En amont de l’opposabilité des dispositions de l’AI Act, la Commission européenne a proposé en septembre 2024 un Pacte pour l’IA ou AI Pact reposant sur les engagements volontaires des entreprises afin de créer une communauté collaborative qui facilite la mise en oeuvre proactive de certaines mesures ainsi que la communication.
Selon la page d’un site officiel du gouvernement, ce « pacte européen sur l’IA ressemble à une vaste blague ». L’UE qui chercherait « par tous les moyens à rallier les entreprises à sa grande cause, à savoir l’application de son règlement sur l’intelligence artificielle » utiliserait ce pacte d’engagements volontaires « dont personne ne vérifiera s’ils sont respectés pour brosser ses signataires dans le sens du poil ». OpenAI serait même un « parfait exemple de l’hypocrisie » des grandes entreprises du numérique puisque « la société la plus en vogue du marché se targue de soutenir les priorités fondamentales du pacte » alors que son propre comité d’éthique, de sûreté et de sécurité est composé de membres de son conseil d’administration.
Les rapporteurs soulignent que plusieurs entreprises ont tout de même refusé de rejoindre ce pacte pourtant proposé sous la forme de simples engagements volontaires, marquant par-là leur opposition à la démarche de la Commission européenne, à l’instar d’Apple et de Meta.
Parallèlement à ce Pacte pour l’IA, l’UE débute ses travaux sur la rédaction de codes de bonnes pratiques qui doivent aboutir au plus tard le 2 mai 2025. La Commission européenne et son Bureau de l’IA ont ainsi lancé le 30 septembre 2024 ces travaux, qui devraient s’appuyer sur un panel scientifique d’experts indépendants, avec notamment pour objectif de préciser les règles de classification et le cadre applicable aux modèles d’IA à usage général en distinguant parmi eux ceux présentant un risque systémique ; de proposer des outils d’évaluation des risques et des mesures d’atténuation ; d’établir des modalités de transparence et de respect des droits d’auteur.
b) Deux projets de directive complémentaires à l’AI Act : l’intelligence artificielle comme produit sur le marché unique
En parallèle de l’adoption de l’AI Act, les institutions européennes discutent de deux projets de directives pour définir des règles en matière de responsabilité civile extracontractuelle pour l’IA. Ces textes, qui ont pour objet de protéger les utilisateurs, sont complémentaires de l’AI Act – surtout axé sur la prévention des risques – et y renvoient directement.
Alors que les règles nationales en matière de responsabilité pour faute obligent la victime à prouver l’existence d’un acte préjudiciable ou d’une omission de la part de la personne qui a causé le dommage, le fonctionnement des systèmes d’IA rend difficile une telle identification.
Ceci est particulièrement préoccupant pour les TPE et PME qui ne peuvent pas se permettre d’avancer des frais dans une procédure pour obtenir des réparations. Ainsi, il est proposé d’adapter la politique de responsabilité du producteur du fait des produits défectueux en visant une harmonisation des régimes de responsabilité pour l’IA au sein de tous les pays de l’UE.
La directive 2022/0302 est une révision de la directive 85/374/CEE. Elle considère les systèmes d’IA et les biens dotés d’IA comme des « produits » sur le marché. De ce fait, les personnes lésées par un système d’IA défectueux peuvent obtenir des réparations sans qu’elles n’aient à prouver la faute du fabricant. Le demandeur doit prouver la défectuosité du produit, le dommage subi et le lien de causalité entre la défectuosité et le dommage.
La directive 2022/0303 introduit de nouveaux concepts dans le cas de responsabilité civile en réparation de dommages causés par une faute extracontractuelle. La logique de cette directive est proche de celle citée ci-dessus, elle vise aussi à faciliter l’obtention de réparations. D’une part, un demandeur lésé peut demander la divulgation d’éléments de preuve de la part du défendeur qui opère un système d’IA, d’autre part, si cette demande n’est pas satisfaite, il y a présomption de non-respect du devoir de vigilance pour le défendeur.
Le demandeur qui a été lésé peut en effet saisir les juridictions nationales pour qu’elles ordonnent la divulgation d’éléments de preuve pertinents concernant un système d’IA à haut risque soupçonné d’avoir causé un dommage. Pour cela, le demandeur doit présenter des éléments de preuve suffisants pour étayer la plausibilité d’une action en réparation. Un défendeur qui ne divulguerait pas ces informations aux instances compétentes serait présumé avoir manqué à son devoir de vigilance pertinent, ce qui constitue une faute, à moins qu’il ne parvienne à renverser cette présomption.
Par cette présomption réfragable, les juridictions nationales présument le lien de causalité entre la faute du défendeur et le résultat produit par un système d’IA ou son incapacité à produire un résultat. Pour cela, les trois conditions prévues à l’article 4 de la directive doivent être remplies :
– le demandeur ou la juridiction a présumé la faute du défendeur de manquement à son devoir de vigilance ;
– l’influence de la faute sur le résultat du système d’IA ou son incapacité à produire un résultat est « raisonnablement probable » ;
– le demandeur a pu prouver que le dommage a pour origine le résultat du système d’IA ou son incapacité à produire un résultat.
Dans le cas des IA à risque élevé, le manquement du défendeur à son devoir de vigilance est encore plus facile à démontrer pour le demandeur : il suffit que ces systèmes ne respectent pas les obligations fixées par la réglementation sur l’IA. Ces systèmes doivent être transparents, pouvoir être contrôlés, avoir un niveau approprié d’exactitude et pouvoir être rappelés ou retirés.
c) Le soutien européen à la recherche et à l’innovation en IA au-delà du dispositif EuroHPC
EuroHPC est l’entreprise commune pour le calcul à haute performance européen (European high-performance computing joint undertaking ou EuroHPC). Cette entreprise est un partenariat public-privé créé par un règlement de l’Union européenne du 28 septembre 2018, permettant la mise en commun de ressources à l’échelle européenne. L’objectif de l’entreprise est défini à l’article 3 du règlement : « La mission de l’entreprise commune est de créer, de déployer, d’étendre et de conserver dans l’Union une infrastructure intégrée de supercalcul et de données de classe mondiale, ainsi que de mettre en place et de soutenir un écosystème hautement compétitif et innovant en matière de calcul à haute performance ».
Pour financer ces infrastructures, l’Union européenne investit 486 millions d’euros et les États membres s’engagent à contribuer chacun à hauteur de 10 millions d’euros au minimum. Les entreprises privées, quant à elles, doivent financer à due proportion l’EuroHPC. Le texte distingue deux types de supercalculateurs selon leur puissance de calcul : les pétaflopique (de 1 pétaflop, soit 1015 FLOPS, à 100 pétaflops soit 1017 FLOPS), d’une part, et les pré-exaflopique (de 100 pétaflops à un exaflop, soit 1018 FLOPS), d’autre part. L’entreprise permet aux pays de financer 50 % des coûts d’acquisition et 50 % des coûts d’exploitation des supercalculateurs pré-exaflopiques et 35 % des coûts d’acquisition des supercalculateurs pétaflopiques.
En contrepartie de ces financements, l’Union européenne dispose de 50 % du temps d’accès aux supercalculateurs, proportionnellement à sa contribution financière, qu’elle distribue entre chaque État membre participant au consortium européen.
Le soutien européen à la recherche et à l’innovation en IA s’étend également à d’autres initiatives. Le 10 septembre 2024, la Commission européenne a lancé un appel à propositions pour la mise en place de fabriques d’IA ou AI Factories. Un réseau européen d’écosystèmes d’IA conjuguant puissance de calcul, accès aux données et talents des développeurs devrait ainsi éclore en 2026. La Commission européenne compte sur l’accélération du développement d’espaces européens communs des données, mis à la disposition de la communauté de l’IA.
L’Union européenne a également annoncé au début de l’année 2024 un soutien financier à l’IA générative, accordé par la Commission dans le cadre d’Horizon Europe et du programme pour une Europe numérique. Ce paquet mobiliserait environ 4 milliards d’euros d’investissements publics et privés d’ici à 2027.
Dans la continuité du consortium « AI4EU » lancé en 2019, l’initiative « GenAI4EU » devrait soutenir le développement de nouveaux cas d’utilisation et d’applications émergentes liés à l’IA générative dans 14 écosystèmes industriels européens, ainsi que dans le secteur public. Les domaines d’application comprennent la robotique, la santé, les biotechnologies, l’industrie manufacturière, la mobilité, le climat et les mondes virtuels.
L’Union européenne poursuivra par ailleurs la promotion des investissements publics et privés dans les start-up dans le domaine de l’IA, à l’aide de soutien en capital-risque ou en fonds propres, y compris au moyen de nouvelles initiatives dans le cadre du programme d’accélération du CEI et d’InvestEU.
En outre, deux consortiums pour une infrastructure numérique européenne (EDIC) sont mis en place : d’une part, une Alliance pour les technologies du langage (ALT-EDIC qui doit promouvoir la diversité linguistique et la richesse culturelle de l’Europe et soutenir l’élaboration de grands modèles de langage européens par une infrastructure commune remédiant à la pénurie de données langagières européennes pour l’entraînement des IA), d’autre part l’EDIC «CitiVERSE», qui utilisera des outils d’IA de pointe pour les Smart Cities afin de mettre au point des jumeaux numériques, aidant les villes à simuler et à optimiser certaines de leurs politiques, notamment la gestion des transports et des déchets.
PANORAMA D’AUTRES RÉGULATIONS NATIONALES DANS LE RESTE DU MONDE
1. Aux États-Unis, une régulation inachevée
a) Au niveau fédéral : de la stratégie de 2016 à l’Executive Order présidentiel d’octobre 2023
Depuis la stratégie fédérale américaine pour l’IA et sa vingtaine de recommandations dévoilée en octobre 2016 par le Président Barack Obama, aucune loi encadrant l’IA n’a été votée aux États-Unis. Il est vrai qu’en octobre 2016, le Président américain n’était pas favorable à l’adoption d’un cadre législatif contraignant : « si vous parlez à Larry Page, le cofondateur de Google ou aux autres, leur réaction en général, et on peut les comprendre, c’est “la dernière chose que nous voulons c’est que des bureaucrates viennent nous ralentir pendant que nous chassons la licorne” ».
En dépit de ce discours, plusieurs projets de « bills » ont été déposés au cours de ces dernières années, comme l’ont expliqué les sénateurs et les représentants américains rencontrés par les rapporteurs au Congrès à Washington : la sénatrice Marsha Blackburn du Tennessee, le sénateur Mike Rounds du Dakota du Sud, co-président du groupe sénatorial sur l’IA, le sénateur Todd Young de l’Indiana et la représentante Anna Eshoo de Californie.
Tous ne sont pas convaincus de l’intérêt de légiférer au niveau fédéral. Seule Anna Eshoo se prononce pour une législation bipartisane fédérale complète en matière d’IA. Marsha Blackburn, bien qu’opposée à une régulation verticale de l’IA et aux dispositions de l’AI Act de l’UE, souhaite des législations fédérales sectorielles, notamment un cadre américain en faveur de la protection des données personnelles.
Elle a par exemple déposé un projet de texte bipartisan avec Chris Coons, Amy Klobuchar et Thom Tillis en faveur d’un No Fake Act, protégeant notamment les artistes. De même Mike Rounds souhaite que le Congrès identifie une solution législative fédérale pour protéger et rémunérer les titulaires de droits de propriété intellectuelle, comme les détenteurs de droits d’auteur (copyrights) et de brevets.
De manière plus large, Todd Young travaille conjointement avec les sénateurs Schumer, Heinrich et Rounds à une feuille de route pour orienter, dans une logique bipartisane, les travaux du Sénat américain en matière d’IA. En 2023, Todd Young a introduit une proposition de loi pour l’Algorithmic Accountability afin d’encadrer l’utilisation de prises de décision automatisées dans des situations à incidence forte pour les secteurs du logement, des finances, de l’emploi et de l’éducation. Ce texte prévoit aussi la création d’un bureau de la technologie au sein de la Federal Trade Commission qui serait chargé de veiller à l’application et à la mise en oeuvre de la loi.
Il n’existe donc pas encore de lois encadrant l’IA aux États-Unis mais le 30 octobre 2023, le Président des États-Unis a cependant signé un Executive order, décret présidentiel à portée générale, dénommé « Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence».
Le texte vise le développement et l’utilisation de systèmes d’intelligence artificielle sûrs et fiables. Il s’agit d’un document assez long (le plus long de tous les décrets présidentiels jamais publiés) qui a principalement pour objet d’encadrer les modèles de fondation présentant des risques pour la sécurité, l’économie ou la santé. Il est surtout contraignant pour les administrations et agences fédérales.
Il demande aux entreprises développant ces modèles de les notifier au gouvernement fédéral et de partager les résultats de leurs tests. Ce premier axe conforte la dynamique d’engagements volontaires en faveur d’une IA « sûre, sécurisée et digne de confiance » obtenus en amont de l’adoption du décret par l’exécutif américain de la part de 15 entreprises (sept entreprises en juillet 2023, soit Amazon, Anthropic, Google, Inflection, Meta, Microsoft et OpenAI rejointes par huit autres en septembre 2023, soit Adobe, Cohere, IBM, Nvidia, Palantir, Salesforce, Scale AI et Stability).
Le texte prévoit aussi des obligations de déclaration pour les modèles dont les entraînements sont jugés à risque « systémique », en retenant un seuil plus élevé que l’AI Act européen (et donc plus souple en termes de contraintes pour les entreprises que le règlement européen) puisque le seuil de puissance de calcul est fixé à 1026 flop/s au lieu de 1025 flop/s pour le seuil européen.
Le décret confie, par ailleurs, au ministère du commerce la responsabilité de préparer des lignes directrices sur l’authentification des contenus et les filigranes ou watermarking afin de reconnaître les contenus générés par une IA.
Ce ministère abrite désormais, au sein de son National Institute of Standards and Technology (NIST), l’Institut américain pour la sécurité de l’IA (US AI Safety Institute ou AISI), dont les responsables ont été entendus, chargé d’« élaborer des lignes directrices, évaluer les modèles et poursuivre des recherches fondamentales (…) pour faire face aux risques et saisir les opportunités de l’IA ».
L’AISI a été fondé en novembre 2023, dès le lendemain de la signature du décret présidentiel sur le développement et l’utilisation d’une intelligence artificielle sûre et fiable. En février 2024, la conseillère à la politique économique de Joe Biden, Elizabeth Kelly, a été nommée à la tête de l’Institut.
En février 2024, le gouvernement américain a aussi créé de façon complémentaire le US AI Safety Institute Consortium (AISIC), regroupant plus de 200 organisations telles que les géants du secteur, Google, Anthropic ou Microsoft. En mars 2024, un budget de 10 millions de dollars lui a été alloué. Les observateurs ont noté la faiblesse de ce financement, surtout si l’on considère la puissance des grandes sociétés de la Tech et de l’IA aux États-Unis. Le NIST lui-même, qui accueille l’AISI, est également connu pour son manque chronique de financement.
D’autres aspects de l’Executive order peuvent être mentionnés. Il appelle à une plus grande protection des données personnelles et des droits des consommateurs et exige de toute l’administration fédérale et des agences gouvernementales d’être exemplaires dans leur utilisation de l’IA.
La dernière partie du décret appelle à « des actions supplémentaires » et affirme la volonté de l’exécutif de travailler avec le Congrès « en vue d’une législation bipartisane ».
Le NIST, dans le cadre duquel travaille l’AISI, largement à l’origine du texte de l’Executive order, avait déjà publié en 2023, avant le décret, un ensemble de lignes directrices non contraignantes intitulé US AI Risk Management Framework, afin de gérer les risques liés à l’IA et à accroître la confiance dans les systèmes d’IA en formalisant une série de bonnes pratiques au stade de leur conception, de leur développement, de leur entraînement et de leur utilisation. Il peut également être relevé qu’en octobre 2022, l’Office of Science and Technology Policy de la Maison-Blanche a publié un « Blueprint for an AI bill of rights » qui fait figure de projet de déclaration des droits pour la protection des citoyens américains vis-à-vis de l’IA. Il contient ainsi cinq principes : « des systèmes sûrs et efficaces », « une protection contre la discrimination algorithmique », « la confidentialité des données », « la notification et l’explication des décisions », « les alternatives humaines, la considération et le retour en arrière ».
Pour conclure, en dehors de ces dispositifs réglementaires et de ces lignes directrices, les États-Unis n’ont pas encore de législation fédérale sur l’IA, en dépit de plusieurs propositions en ce sens. Pour autant, différents États cherchent, à une échelle plus locale, à aller plus vite et plus loin que les initiatives fédérales, notamment pour lutter contre les deepfakes pendant les élections.
b) Au niveau des États : plusieurs projets à commencer par celui de la Californie
Le Colorado, l’Utah, l’Illinois, le Massachusetts, l’Ohio et la Californie ont élaboré des textes pour réglementer le développement et l’utilisation de l’IA, notamment l’IA générative et les systèmes à risque élevé.
Le projet le plus intéressant est celui de la Californie sur la régulation des modèles d’IA générative, connu sous le nom de California AI Bill adopté par le Sénat et l’Assemblée de l’État, mais auquel le gouverneur Gavin Newsom a opposé son véto le 29 septembre 2024. Le texte, qui s’appliquait à tous les développeurs de systèmes d’IA offrant des services en Californie, indépendamment du lieu de leur siège social, n’a donc pas pu être promulgué.
Contrairement à l’AI Act de l’UE et aux lois chinoises, canadiennes et brésiliennes, ses dispositions visaient uniquement les modèles d’IA à risque systémique, définis selon un coût d’entraînement ou un seuil de puissance de calcul et non par les risques dans l’utilisation des systèmes. Le champ concernait ainsi les modèles d’IA ayant nécessité un coût de plus de 100 millions de dollars d’entraînement de leur seul modèle de fondation ou de plus de 10 millions de dollars de réglage fin (fine-tuning) ou encore une puissance de calcul supérieure à 1026 FLOPS.
Les développeurs de tels modèles auraient alors eu à respecter de nombreuses exigences en termes de transparence et de tests de sécurité. En cas de non-conformité, ils se seraient exposés à des sanctions financières élevées, pouvant aller jusqu’à 10 % du coût de la puissance de calcul utilisée pour entraîner le modèle. Un modèle ayant nécessité un milliard de dollars aurait par exemple pu exposer son développeur à une amende de 100 millions de dollars. Le projet prévoyait aussi un dispositif de Kill Switch pour désactiver une IA en cas de problèmes.
Le véto du gouverneur le 29 septembre 2024 fait suite à une lettre des grands groupes de l’IA, à commencer par Microsoft, Google ou Meta, qui dénonçaient des exigences de sécurité trop vagues quant aux tests obligatoires à réaliser pour les développeurs de modèles. Les risques financiers encourus par ces entreprises en raison de l’engagement de leur responsabilité en cas de dommages causés par leurs systèmes d’IA faisaient aussi partie des motifs de leurs réserves.
Malgré ce véto qui marque la fin de l’année 2024, l’État de Californie a d’ores et déjà adopté pas moins de 17 autres nouvelles lois spécifiques ou sectorielles dans la période récente, encadrant divers aspects des technologies d’IA, comme la désinformation, la lutte contre les deepfakes, la protection des données personnelles, la protection des consommateurs, la protection des enfants ou la lutte contre la pédophilie.
2. En Chine, un développement rapide et centralisé de l’IA et de sa régulation
a) La politique chinoise en faveur d’une IA maîtrisée depuis 2017
La Chine a identifié l’intelligence artificielle comme un domaine stratégique dès 2015, avec des plans tels que « Internet+ » et « Made in China 2025 ». Après le plan d’action pour l’Internet Plus dans lequel l’IA occupe une place (2016-2018), un plan ambitieux de développement pour l’IA de nouvelle génération est adopté en juillet 2017 visant à faire de la Chine le leader mondial de l’IA d’ici 2030. Les investissements publics sont fixés entre 10 et 15 milliards de dollars par an, et un cadre juridique se construit peu à peu.
En 2019, une Commission nationale pour la gouvernance de l’intelligence artificielle est mise en place et a proposé huit principes de gouvernance en faveur du développement d’une IA responsable, concernant tant la protection de la vie privée ou la sécurité que le contrôle et la transparence des algorithmes. La même année, le Consensus de Pékin a établi des principes éthiques pour l’IA, visant surtout l’éducation.
En 2021, la Commission nationale pour la gouvernance de l’intelligence artificielle a publié des normes éthiques pour l’intelligence artificielle de nouvelle génération. Ces principes ont été suivis d’un cadre établi en 2021 par la Cyberspace Administration of China (CAC) ainsi que d’une liste de normes définies par le National Information Security Standardization Technical Committee (dite « TC260 »).
Un décret interministériel sur les algorithmes et leurs recommandations a été publié en décembre 2021, dans la continuité des travaux du CAC, avec une entrée en vigueur le 1er mars 2022. Outre l’enregistrement des systèmes, la fourniture d’informations et l’évaluation de ceux-ci, le décret prévoit l’interdiction de certains usages et, plus largement, un cadre de classification des algorithmes basé sur des facteurs tels que l’influence sur l’opinion publique et les mobilisations sociales ou leur impact sur les comportements des utilisateurs. Une loi sur la protection des informations personnelles a parallèlement été promulguée le 20 août 2021.
Parmi les plans d’orientation existants, il faut aussi mentionner le cadre global du plan quinquennal 2021-2025. Ce dernier reconnaît l’IA comme essentielle pour la sécurité nationale et le développement du pays, avec des applications dans la cybersécurité, la défense, et des secteurs civils comme les villes intelligentes et l’agriculture intelligente. Les subventions du ministère de la science et des technologies (MOST) et de la Commission nationale du développement et de la réforme (NDRC) soutiennent notamment ces initiatives.
En 2023 et 2024, la jurisprudence chinoise a prévu que les contenus originaux générés par l’IA pouvaient conduire à reconnaître l’existence de droits d’auteur et à protéger, par exemple, les images créées (les prompts sont retenus comme créateurs d’une oeuvre originale), en revanche les oeuvres élaborées avec l’assistance d’IA générative qui ressemblent trop à des oeuvres existantes ou, pire, qui les copient purement et simplement font l’objet d’une répression, les fournisseurs des services d’IA pouvant même voir leur responsabilité engagée.
b) Un encadrement strict et assez exhaustif des IA génératives
En novembre 2022, un décret interministériel sur l’encadrement des technologies de synthèse profondes, également pris dans la continuité des travaux du CAC, vise les contenus engendrés par l’IA générative même si son champ d’application est plus large. Il s’agit notamment de lutter contre les fausses informations et les deepfakes en prévoyant un régime de sanctions. Le décret prévoit notamment l’obligation d’ajouter des filigranes ou watermarking pour les contenus générés par l’IA. Il peut être noté que ce décret a été publié cinq jours avant le lancement de ChatGPT.
En juillet 2023, la Cyberspace administration of China (CAC) a publié en coopération avec plusieurs ministères et administrations des mesures administratives provisoires pour la gestion des services d’IA générative, prévoyant, au terme de vastes consultations, des réglementations spécifiques sur les algorithmes, les deepfakes et la standardisation des bases de données.
Les dispositions de ce cadre récent – et postérieur à la diffusion des IA génératives auprès du grand public – sont dans la continuité des textes précédents tout en étant plus détaillées.
Les entreprises proposant des services d’intelligence artificielle sont ainsi soumises à des obligations strictes en termes de transparence, de précision, d’efficacité et de respect de normes éthiques de leurs modèles, ces entreprises pouvant même faire l’objet de contrôles et d’inspections périodiques les conduisant à expliquer le détail des sources, des mécanismes de fonctionnement et des modalités d’entraînement de leurs modèles. Sont également énumérées les attentes lors de la phase d’entraînement des algorithmes, en termes de gestion des données et d’annotation des données d’entraînement.
La lutte contre les activités illégales est renforcée, notamment l’interdiction de la création de contenus illégaux ou immoraux ou encore portant atteinte aux droits de la propriété intellectuelle, et, au-delà, les services d’IA générative doivent enfin respecter les valeurs socialistes. Les utilisateurs et leurs données sont davantage protégés.
Il est réaffirmé que les contenus générés par l’IA doivent clairement indiquer via des filigranes ou watermarking qu’ils ont été générés par ce biais. Le National Information Security Standardization Technical Committee (dite « TC260 ») a été mandaté pour préciser les modalités de déploiement de ces techniques de marquage. Les normes proposées en août 2023 distinguent désormais deux types de techniques de filigrane, l’une explicite, l’autre implicite, c’est-à-dire imperceptible à l’oeil humain mais pouvant être extraite comme une métadonnée à travers des méthodes techniques.
Il est prévu que ce marquage implicite inclut au moins le nom du système ayant offert le service et peut contenir des détails additionnels tels qu’un identifiant unique. En cas de téléchargement du contenu sous la forme d’un fichier, les métadonnées doivent obligatoirement prévoir des informations complémentaires, telles que des détails sur le système ayant offert le service, l’heure et la date de production, ou encore un identifiant unique.
En septembre 2023, le ministère chinois de la science et de la technologie a adopté avec le concours de neuf agences gouvernementales des « Mesures pour la revue éthique des activités scientifiques et technologiques », qui mentionnent notamment les évaluations éthiques rigoureuses des activités recourant à l’IA, à travers par exemple la mise en place de comités d’éthique.
Plus récemment, le TC260 a rendu public le 29 février 2024 des « Exigences fondamentales de sécurité pour les services d’IA générative ».
Dans ce document, 31 risques sont identifiés à travers cinq catégories : les contenus violant les valeurs socialistes, les contenus discriminatoires, les contenus portant atteinte au droit commercial, les contenus portant atteinte aux droits individuels et les contenus ne respectant pas les obligations réglementaires en termes de sécurité. Ce texte oblige les fournisseurs de services d’IA à prendre plusieurs mesures en ce sens et à mettre en oeuvre différents mécanismes d’évaluation.
En complément des règles nationales, les provinces et municipalités chinoises édictent également des règles locales. Ainsi, Shenzhen, Shanghai, Guangdong, Jiangsu et Zhejiang ont adopté des mesures pour encadrer l’IA.
c) Un rival sérieux des États-Unis intéressé par l’AI Act
La Chine est leader dans des domaines clés d’application de l’IA tels que la santé, les voitures autonomes, l’automatisation industrielle, les villes intelligentes ou surtout les technologies de reconnaissance faciale.
La Chine fait la course en tête avec les États-Unis en apprentissage automatique et les devance même en nombre de publications, en analyse de données avancée et en algorithmes et logiciels d’accélération. Les États-Unis sont toujours en avance dans la conception des circuits intégrés et dans le traitement du langage naturel. La Chine vise donc à développer des modèles de LLM rivalisant avec ChatGPT, comme WuDao 2.0 et ErnieBot.
Elle cherche aussi à s’affranchir de sa dépendance aux GPU américaines, surtout que les États-Unis interdisent depuis trois ans l’exportation vers la Chine des puces les plus avancées et même des outils de gravure. La Chine recommande donc depuis 2024, à travers des instructions de son ministère de l’industrie et des technologies de l’information, de privilégier ses alternatives nationales, comme les puces conçues par Huawei.
Les géants de l’IA chinois, les BATXH – pour Baidu, Alibaba, Tencent, Xiaomi, et Huawei – dominent la chaîne de valeur de l’IA dans le pays et possèdent leurs propres centres de recherche. Huawei, par exemple, développe des puces pour pallier les restrictions à l’exportation de technologies de lithographie avancée, bien que l’accès à des fonderies avancées reste un défi.
La production scientifique en IA en Chine est en croissance, avec des recherches axées sur les algorithmes, la vision par ordinateur, les systèmes de recommandation, et les robots. Les chercheurs chinois publient plus que les chercheurs américains en apprentissage automatique. La France y est reconnue pour son haut niveau académique en IA, avec des accords de formation entre les deux pays et un intérêt des entreprises pour nos chercheurs.
Il faut, enfin, relever que la Chine a mis en place une stratégie à long terme pour non seulement attirer et retenir ses talents mais même favoriser leurs retours. Il s’agit essentiellement, d’une part, du plan « Made in China 2025 » dont le but est de faire de la Chine le leader mondial des technologies de pointe, créant ainsi de nombreuses opportunités pour les ingénieurs et les chercheurs et, d’autre part, du concept de « rêve chinois », un concept nationaliste visant à renforcer le sentiment d’appartenance et à encourager les Chinois de la diaspora à revenir contribuer au développement de leur pays.
Le gouvernement chinois a, de plus, mis en place des programmes pour « les Chinois de retour » en vue de faciliter le retour de chercheurs et d’entrepreneurs chinois. En outre, tout comme en Inde, les zones économiques spéciales (ZES) chinoises jouent un rôle crucial dans l’attraction des investissements étrangers et la création d’emplois qualifiés.
L’IA est, en conclusion, perçue en Chine comme un moteur de croissance et un outil stratégique. La rivalité avec les États-Unis est souvent mise en avant par les médias, tandis que la protection des données et de la vie privée n’est pas une préoccupation majeure pour le public. Les régulations européennes, comme le RGPD et l’AI Act, intéressent les régulateurs chinois pour leurs approches ambitieuses. Ils suivront donc avec intérêt la mise en oeuvre du règlement.
3. Quelques autres initiatives intéressantes
Comme l’indique Florence G’Sell, auditionnée par les rapporteurs à l’Université de Stanford, les initiatives prises en matière de régulation de l’IA permettent de distinguer trois groupes de pays :
– ceux qui font le choix d’adopter un cadre strict de régulation de l’IA, comme l’UE, la Chine, le Canada ou le Brésil ;
– ceux qui font le choix d’avancer progressivement dans la voie de la régulation, comme les États-Unis, le Japon, la Corée du Sud et l’Inde ;
– et ceux qui, pour le moment, excluent la perspective de régulations contraignantes, comme le Royaume-Uni, Israël, l’Arabie Saoudite et les Émirats arabes unis.
a) Le Canada
Le Canada, pays doté d’une recherche fondamentale en IA d’excellent niveau, est toujours en train de mettre au point sa première législation complète en matière d’IA. Le vote du projet de loi sur l’intelligence artificielle et les données (Artificial Intelligence and Data Act – AIDA) a pris du retard puisque, déposé en 2022, il a seulement passé le stade de la deuxième lecture fin 2023. Il s’agit d’assurer le développement et l’utilisation de systèmes d’IA responsables au Canada.
Ce projet de loi devrait se traduire in fine par un cadre assez proche du règlement de l’Union européenne du 13 juin 2024 établissant des règles harmonisées concernant l’intelligence artificielle. Les systèmes d’IA y seront distingués des modèles de Machine Learning. Et un encadrement spécifique sera élaboré pour les systèmes d’IA à usage général (modèles d’IA à usage général dans l’Union européenne). On y retrouvera aussi une approche basée sur les niveaux de risque. Un système d’IA pourra être à usage général ou pas et à haut niveau de risque ou pas. Les systèmes conjuguant usage général et haut niveau de risque seront particulièrement encadrés.
Le projet de loi prévoit également la création d’un commissaire à l’intelligence artificielle et aux données, qui aura pour mission d’aider le ministre de l’innovation, des sciences et de l’industrie et sa tutelle le ministère de l’innovation, des sciences et du développement économique, à mettre en oeuvre les dispositions du texte. Ce commissaire pourra prononcer des injonctions et même infliger des amendes.
Avant l’adoption définitive du projet de loi sur l’intelligence artificielle et les données, présenté il y a déjà deux ans, le Canada a adopté pour l’heure, en septembre 2023, un code de conduite pour le développement et la gestion responsables des systèmes d’IA générative avancés.
Ce code, qui repose sur la participation volontaire des entreprises, sert depuis un an de dispositif provisoire en attendant que le Canada finalise son cadre législatif. Il est d’une nature similaire à l’AI Pact de l’Union européenne.
Le Québec, de son côté, a avancé plus vite que le gouvernement fédéral avec une réforme des lois sur la protection des renseignements personnels, obligeant à informer les utilisateurs de l’utilisation de processus de prise de décision automatisés ou qui recueillent de l’information à l’aide d’outils technologiques permettant de les identifier, de les localiser ou d’effectuer leur profilage. De plus, en janvier 2024, le Conseil de l’innovation du Québec a remis au ministère de l’économie un rapport pour un encadrement réglementaire de l’IA.
b) Le Brésil
L’action du gouvernement fédéral brésilien débute en 2019 avec le lancement de la stratégie brésilienne d’intelligence artificielle (dite « EBIA »). Cette stratégie consiste notamment en un travail de préparation de lois fédérales brésiliennes pour promouvoir une utilisation responsable et éthique de l’IA au Brésil. Dès 2020, le Congrès national brésilien a commencé à examiner un projet de loi visant à établir le « cadre juridique de l’intelligence artificielle ». Ce projet de loi a été le premier d’une série de quatre projets proposés au Congrès. Des exceptions à cet encadrement sont prévues pour le data mining.
Le choix du Brésil d’établir un véritable cadre juridique pour l’intelligence artificielle a été directement influencé par la réflexion conduite au sein de l’Union européenne depuis 2018 puis par le contenu du projet de règlement sur l’intelligence artificielle de la Commission européenne d’avril 2021, devenu le règlement de l’Union européenne du 13 juin 2024.
En avril 2024, le Sénat brésilien a annoncé que sa commission temporaire interne sur l’intelligence artificielle avait publié un nouveau rapport préliminaire avec une proposition mise à jour pour l’un des quatre projets de loi. Une innovation clé de cette version alternative du projet de loi était la proposition d’un système de surveillance, autour d’un système national de régulation et de gouvernance de l’IA (SIA), coordonné par une autorité compétente nommée par le pouvoir exécutif.
Le 8 mai 2024, l’autorité brésilienne de protection des données (Autoridade Nacional de Proteção de Dados, ANPD) a publié une proposition d’amendement au projet de loi prévoyant la notion de « système d’IA à usage général », proche de la notion de modèle d’IA à usage général retenue par l’AI Act. Elle a en effet défini ces systèmes comme un « système d’IA basé sur un modèle formé avec des bases de données à grande échelle, capable d’effectuer une grande variété de tâches différentes et de servir à différentes fins, y compris celles pour lesquelles il n’a pas été spécifiquement conçu ou formé, et qui peut être utilisé dans différents systèmes ou applications ».
Le cadre juridique choisi par le Brésil pour réguler l’intelligence artificielle reprend aussi l’approche selon les niveaux de risque, dans le même esprit que les dispositions contenues dans le règlement de l’Union européenne du 13 juin 2024.
c) Le Japon
Le Japon ne dispose pas actuellement d’une loi globale réglementant le développement ou l’utilisation des systèmes d’IA. Toutefois, le gouvernement japonais a établi plusieurs séries de lignes directrices non contraignantes qui sont généralement applicables à des activités précises et a encouragé les efforts volontaires des parties prenantes de l’IA.
Il aborde au fond les risques associés à l’IA de deux manières : par les lignes directrices non contraignantes précitées et par l’application des lois sectorielles existantes. Le Japon a par exemple élaboré des lignes directrices sur la protection des données et des lois sur le droit d’auteur afin de faciliter la conformité au droit des parties prenantes de l’IA. La loi japonaise sur le droit d’auteur autorise en principe l’utilisation d’oeuvres protégées par le droit d’auteur pour la formation de modèles d’IA sans l’autorisation du titulaire du droit d’auteur.
En juillet 2021, le ministère de l’économie, du commerce et de l’industrie (METI) a publié un rapport indiquant que « du point de vue de l’équilibre entre le respect des principes de l’IA et la promotion de l’innovation, et du moins à l’heure actuelle, à l’exception de certains domaines spécifiques, la gouvernance de l’IA devrait être conçue principalement avec de la soft law, favorable aux entreprises qui respectent les principes de l’IA ». Le document précise que « les exigences horizontales juridiquement contraignantes pour les systèmes d’IA sont jugées inutiles pour le moment ».
Cette approche, reposant sur des lignes directrices non contraignantes, découle de la conviction que les lois contraignantes ne peuvent pas suivre le rythme rapide et la complexité du développement de l’IA et pourraient même étouffer l’innovation en matière d’IA.
En février 2024, les autorités japonaises ont toutefois lancé des discussions sur l’élaboration d’une législation contraignante, un cadre qui imposerait différentes obligations aux développeurs de modèles fondamentaux à grande échelle.
d) La Corée du Sud
La Corée du Sud a annoncé des objectifs ambitieux pour devenir un leader mondial de la technologie de l’IA. Elle ne dispose actuellement d’aucune loi ou politique spécifique pour encadrer l’intelligence artificielle. Pour parvenir à être un leader mondial, son approche de la régulation de l’IA est en effet animée par un principe qui peut être résumé par la formule « Autoriser d’abord, réglementer ensuite ».
Une législation pourrait néanmoins se dessiner puisque son Assemblée nationale se prépare à discuter d’un projet de loi nationale sur l’IA. En attendant, la Corée du Sud veille à la mise en oeuvre de ses normes éthiques en matière d’IA et prend des mesures pour mettre en oeuvre sa stratégie pour une IA digne de confiance. Les agences coréennes ont pris des mesures proactives pour établir des lignes directrices sur l’IA et appliquer des mesures de protection des données personnelles aux principaux acteurs de l’IA.
e) L’Inde
L’Inde est l’un des pays asiatiques où l’économie numérique est la plus développée. Ce secteur a connu une croissance rapide au cours des dernières années, notamment à travers une forte augmentation des services numériques. L’Inde a également fait du développement et de l’adoption de l’intelligence artificielle une priorité dans ses initiatives politiques pour l’avenir.
En mars 2024, le gouvernement indien a annoncé une dotation budgétaire de plus de 1,25 milliard de dollars pour la « India AI Mission », qui recouvrira divers aspects de l’IA, notamment les capacités du pays en termes d’infrastructures informatiques, la formation, l’innovation, les jeux de données et le développement d’une IA sûre et fiable.
Les organismes gouvernementaux indiens ont entrepris diverses actions, telles que la publication de rapports ou la promotion d’initiatives visant à favoriser des pratiques et principes responsables en matière d’IA. Ces initiatives peuvent relever de soutiens au niveau fédéral comme au niveau des États et d’autres organismes de réglementation.
L’Inde a accueilli le Sommet du Partenariat mondial sur l’IA, Global Partnership on AI ou GPAI, à New Delhi en décembre 2023 et préside le Sommet en 2024. L’un des résultats du Sommet de 2023 a été la « Déclaration 2023 des ministres », dans laquelle les membres se sont engagés à continuer à oeuvrer à la promotion d’une IA sûre, sécurisée et digne de confiance dans leurs pays.
Le gouvernement indien est également conscient des éventuels risques liés à ces technologies. Après plusieurs années de délibération, il a récemment promulgué une loi nationale sur la protection des données. Des cadres réglementaires pour répondre aux risques de l’IA devraient être prochainement élaborés. Des avis ont d’ores et déjà été émis en 2023 par le ministère indien de l’électronique et des technologies de l’information (MEITY) concernant l’IA générative et les deepfakes. Bien qu’il existe une incertitude quant à la nature juridiquement contraignante ou pas de ces avis, ils donnent une idée du sérieux avec lequel le gouvernement indien se préoccupe de l’IA générative et de la manière dont ces préoccupations pourraient être traitées dans les futures législations et réglementations.
Ces avis, réitérant les obligations déjà existantes en vertu de la loi indienne concernant les mesures que les plateformes doivent prendre pour identifier et prévenir la désinformation, exigent ainsi des plateformes en ligne qu’elles prennent des mesures pour lutter contre les deepfakes et autres contenus de désinformation.
Outre l’identification des contenus de désinformation, la loi interdit de mettre en ligne tout contenu de désinformation et oblige les plateformes à agir sur ces contenus dans les 36 heures. Il s’agit donc en réalité essentiellement d’étendre les obligations existantes aux deepfakes.
Le MEITY a publié un message sur Twitter (rebaptisé X en juillet 2023) indiquant que ses avis de décembre 2023 ont été publiés après la tenue de deux consultations avec les parties prenantes concernées, connues sous le nom de « Dialogues numériques sur l’Inde», portant notamment sur la question de la lutte contre les deepfakes. Un des avis du MEITY conseille par ailleurs aux plateformes de se conformer à diverses exigences de modération du contenu en ligne afin de continuer à bénéficier d’une immunité de responsabilité (protection de la sphère de sécurité) en vertu de la loi indienne.
Enfin, un avis a été émis par le MEITY le 1er mars 2024, exigeant que « tout modèle d’intelligence artificielle/LLM/IA générative, logiciel ou algorithme non fiable » demande préalablement à son déploiement en Inde « l’autorisation explicite » du gouvernement indien. Les entreprises ont également été invitées à soumettre des rapports sur l’état de conformité de leurs systèmes avant le 15 mars 2024.
Cet avis a fait l’objet de nombreuses critiques. Outre une mise en question de sa base juridique et de sa portée précise, diverses parties prenantes ont fait valoir que ses exigences étaient anti-innovation et avaient un impact négatif sur la croissance de l’écosystème indien de l’IA. Cela a incité le ministre indien des technologies de l’information à publier à nouveau un message sur X/Twitter, pour clarifier la portée de l’avis du MEITY puis à publier le 15 mars 2024 un nouvel avis de deux pages, remplaçant le précédent.
Le nouvel avis a supprimé l’obligation de demander l’approbation du gouvernement pour les modèles d’IA générative mais impose aux entreprises de soumettre un rapport sur l’état de conformité des systèmes. Le caractère juridiquement contraignant du nouvel avis reste toujours aussi incertain. Il s’agirait en fait pour les plateformes de plus de 500 000 utilisateurs enregistrés de :
– ne pas afficher ou permettre aux utilisateurs de partager des contenus illégaux ;
– ne pas autoriser de parti pris ou de discrimination ;
– ne pas menacer l’intégrité du processus électoral ;
– d’étiqueter les contenus générés par l’IA qui peuvent inclure de la désinformation ou des deepfakes ;
– d’utiliser des métadonnées pour identifier tout utilisateur qui modifie les informations.
L’Inde cherche, par ailleurs, à faire revenir les talents sur son sol. Longtemps confrontée à un exode de ses meilleurs cerveaux, elle a entrepris des actions significatives pour inverser cette tendance :
– le programme gouvernemental « Start up India, Stand up India » qui vise à promouvoir l’esprit d’entreprise et à créer un écosystème favorable aux start-up. L’objectif est de fournir un environnement propice à l’innovation et de retenir les talents sur le territoire indien ;
– le programme « Diaspora connect » qui cherche à renforcer les liens entre la diaspora indienne et son pays d’origine, en encourageant le retour des talents et les investissements ;
– l’initiative « Make in India » qui encourage les entreprises manufacturières à investir en Inde, créant ainsi de nouveaux emplois qualifiés et des opportunités pour les ingénieurs et les chercheurs indiens ;
– les zones économiques spéciales (ZES), qui bénéficient d’avantages fiscaux et réglementaires pour attirer les investissements étrangers et créer des pôles d’excellence.
f) Le Royaume-Uni
L’écosystème du Royaume-Uni en matière d’IA est le troisième au monde derrière ceux des États-Unis et de la Chine. Depuis 2022, le secteur technologique britannique est le troisième à atteindre une valorisation de plus de 1 000 milliards de dollars, après les États-Unis et la Chine. Une fiscalité avantageuse encourage ce dynamisme (EIS, SEIS, Business Asset, Disposal Relief…) tout comme la présence de plus de 400 incubateurs.
Le secteur de l’IA compte 3 170 entreprises (60 % spécialisées dans l’IA et 40 % diversifiées) dont environ 50 start-up dans la seule IA générative. Il générerait 3,7 milliards de livres de valeur ajoutée pour l’économie britannique dont 71 % de revenus réalisés par les très grandes entreprises (Microsoft, Google, DeepMind, IBM, etc.). Le Royaume-Uni cherche à garder ses talents et à attirer les talents étrangers.
Le monde de la recherche y est performant et reconnu, bien intégré au secteur privé, notamment autour d’un arc de pointe Londres-Oxford-Cambridge. Certains secteurs à fort potentiel pour l’IA comme les services financiers et les services professionnels sont puissants à Londres. 55 % des entreprises de l’IA se situent donc à Londres même. Un quart environ se trouve en périphérie de Londres.
L’approche du Royaume-Uni en matière de régulation de l’IA est plutôt pro-innovation que pro-réglementation. Les autorités ne souhaitent pas perturber leur riche écosystème. Le Royaume-Uni a annoncé en 2021 un plan sur dix ans pour devenir une superpuissance mondiale de l’IA. Ce plan met l’accent sur un investissement solide dans la recherche et le développement ainsi que sur un cadre de gouvernance qui donnera la priorité à l’innovation et à la gestion des risques.
La stratégie du gouvernement britannique se concentre principalement sur la promotion de l’innovation. Au lieu de mettre en oeuvre une réglementation générale, le gouvernement britannique privilégie une approche souple, contextuelle et intersectorielle fondée sur des principes.
Le Royaume-Uni a ainsi pris des mesures spécifiques pour soutenir la sécurité des produits, la cybersécurité et d’autres domaines et a demandé aux agences publiques de soumettre des orientations conformes à l’approche pro-innovation de la réglementation pour traiter les risques liés à l’IA. Le gouvernement britannique reconnaît que des exigences contraignantes pourraient éventuellement être nécessaires pour atténuer les dommages potentiels liés à l’IA, mais il a également déclaré qu’il n’introduira une législation que lorsqu’une telle mesure lui semblera pleinement justifiée.
L’ancien Premier ministre Rishi Sunak, dans son discours d’octobre 2023 devant la Royal Society, a résumé l’approche du Royaume-Uni par une question : « Comment pouvons-nous rédiger des lois qui aient du sens pour quelque chose que nous ne comprenons pas encore pleinement ? » Il a fait valoir qu’il ne se précipiterait pas pour réglementer l’IA à ce stade.
Le Royaume-Uni continue de publier des conseils et des précautions en termes de sécurité pour les développeurs de l’IA, inspirés par les principes de l’OCDE. Des rapports parus en avril 2024 pourraient inciter le gouvernement britannique à prendre des mesures minimales pour adopter sa propre législation ou réglementation sur l’IA, malgré les propos antérieurs du Premier ministre.
Les étapes de construction de la politique du Royaume-Uni en matière d’IA peuvent être rappelées brièvement. Dès 2015, le pays se dote d’un institut national pour la science des données et l’IA, le Alan Turing Institute, une entité de droit privé indépendante mais financée par le gouvernement.
En 2017, l’IA est identifiée comme l’un des secteurs prioritaires de la stratégie industrielle nationale (UK Industrial Strategy). En 2016, est mis en place l’Institut pour une IA responsable (Responsible AI Institute ou RAI Institute) avec un partenariat public-privé efficace, qui s’est depuis déployé dans un grand réseau conduisant plusieurs initiatives dédiées à la promotion de l’IA, dans une approche multidisciplinaire et multisectorielle. En 2018, un Bureau national de l’IA est créé au sein du ministère de la science, de l’innovation et de la technologie (UK Office for AI).
Avec le AI Sector Deal de 2019, un paquet d’investissements de 1,3 milliard de livres est prévu. La même année, le gouvernement se dote d’un Conseil de l’IA (UK AI Council).
En 2020 est créé le Digital Regulation Cooperation Forum, un forum de coopération volontaire entre les régulateurs du secteur numérique. Son rôle est de coordonner sans fournir de directives à ses membres. Dans un rapport, le Communications and Digital Committee de la House of Lords estime que la création du forum va dans le bon sens mais qu’il ne dispose pas des pouvoirs et moyens suffisants pour répondre aux défis de la régulation de l’IA et du numérique.
En 2021 est adoptée une stratégie nationale pour l’IA, un plan sur dix ans pour faire du Royaume-Uni une « superpuissance de l’IA ». Les soutiens à cet objectif s’accélèrent depuis lors. L’IA est ainsi identifiée en 2023 comme priorité pour la stratégie de croissance du pays. Elle est, de plus, l’une des cinq technologies prioritaires du Science and Technology Framework.
En 2022 est lancée une initiative, appelée AI Standards Hub, dirigée par le Alan Turing Institute et soutenue par la British Standards Institution et le National Physical Laboratory. Elle vise à orienter les débats sur la normalisation et à développer des standards nationaux mais aussi internationaux en rassemblant les différents acteurs de la normalisation (gouvernement, régulateurs, industrie, consommateurs, société civile, etc.).
Elle repose sur quatre piliers : un observatoire qui se dote d’une base de données compilant les normes existantes ou en cours d’élaboration partout dans le monde ; une plateforme communautaire pour faciliter les connexions, la coordination, l’échange d’idées et la résolution collaborative de problèmes entre les parties prenantes ; la constitution d’un matériel d’apprentissage en ligne ainsi que des formations en présentiel afin de familiariser les acteurs avec les normes ; la construction d’une base de recherches et d’études sur les grands enjeux liés au développement de normes dans l’IA.
Le UK AI White Paper sur l’encadrement de l’IA
Les principes clés du AI White Paper pour encadrer de manière souple et pro-innovation les usages de l’IA sont les suivants :
– l’encadrement ne doit pas porter sur les technologies elles-mêmes ou les modèles mais sur les usages de ces modèles et des systèmes d’IA ;
– la régulation de ces usages est confiée à des régulateurs sectoriels et pas à un régulateur unique ;
– cinq principes horizontaux centralisés et non contraignants doivent guider l’action des régulateurs, à savoir 1. la sûreté, la sécurité et la robustesse ; 2. la transparence et l’explicabilité du processus décisionnel ; 3. la compatibilité des systèmes d’IA avec les lois britanniques existantes ; 4. l’existence d’une chaîne de responsabilités clairement établie et d’une gouvernance permettant le contrôle des systèmes d’IA ; 5. la contestabilité et l’existence de voies claires de recours.
En juin 2023, dans un rapport intitulé « Generative AI Framework for HMG », le Central Digital and Data Office du Royaume-Uni a publié des directives spécifiques sur l’IA générative pour la fonction publique britannique. Le rapport énumère 10 principes pour guider l’utilisation responsable de l’IA générative au sein du gouvernement. Ces principes vont de recommandations éthiques (utiliser l’IA générative de manière légale, éthique et responsable) à des recommandations plus pratiques (comprendre comment gérer l’intégralité du cycle de vie de l’IA générative ou avoir les compétences et l’expertise nécessaires pour créer et utiliser l’IA générative).
Le 26 octobre 2023, le roi a donné son assentiment à la promulgation de la loi sur la sécurité en ligne, qui vise surtout la modération de contenu. La loi impose une obligation légale de diligence à deux catégories de services en ligne pour limiter les contenus préjudiciables : les services qui partagent du contenu généré par l’utilisateur (Facebook par exemple) et les services de recherche (comme Google).
En mars 2023, un AI White Paper réitère et précise l’option d’une régulation souple et pro-innovation de l’IA.
À la fin de l’année 2023, dans le cadre du nouveau programme britannique pour une IA responsable (Responsible AI Programme appelé RAI UK) a été lancé un appel à projets pour financer des projets de recherche autour de l’IA responsable. RAI UK cherche aussi à diffuser à l’échelle mondiale les bonnes pratiques applicables aux systèmes d’IA.
En novembre 2023, lors du sommet de Bletchley Park, a été lancé le UK AI Safety Institute, dont des responsables ont été rencontrés par les rapporteurs. Ian Hogarth en est le directeur général et une centaine de chercheurs y sont rémunérés pour effectuer des tests sur les modèles des principales entreprises d’IA, sur la base de leur participation volontaire.
Le UK AI Safety Institute poursuit trois objectifs :
– mener des recherches sur la sécurité des systèmes d’IA ;
– effectuer des tests de sécurité sur les modèles d’IA, avant et après leur mise sur le marché ;
– promouvoir le développement d’un écosystème d’entreprises tournées vers des IA responsables et sécurisées.
Sur la base du volontariat, les entreprises participent à ces tests. Un bac à sable réglementaire a également été mis en place.
Plus récemment, en février 2024, 80 millions de livres ont été alloués au lancement de neuf centres de recherche sur l’IA à travers le pays (recherche mathématique et informatique et IA appliquée à la science, à l’ingénierie et aux données), 9 millions de livres pour un partenariat avec les États-Unis sur la recherche en IA responsable et 2 millions de livres pour le Arts and Humanities Research Council (AHRC) afin de financer la recherche en sciences sociales sur l’IA.
Par ailleurs, avec les AI Safety Summits, dont la première édition s’est tenue à Bletchley Park en novembre 2023, le Royaume-Uni cherche à se placer au centre de la régulation internationale. Rishi Sunak a ainsi déclaré vouloir faire de son pays « le foyer de la réglementation mondiale en matière de sécurité de l’IA ». Ses objectifs étaient à la fois d’installer les institutions britanniques au coeur des dispositifs de régulation internationale de l’IA ; d’attirer les regards de l’ensemble des investisseurs internationaux vers l’écosystème britannique de l’IA ; et de consacrer pour la première fois un sommet international à la question des risques extrêmes posés par les systèmes d’IA de pointe, qu’il s’agisse de mauvais usages de la technologie par des acteurs malveillants (attaques et biosécurité notamment), de futures avancées technologiques vers l’IA générale ou de perte de contrôle humain sur les machines.
Plusieurs institutions internationales ainsi que 30 pays, dont les États-Unis et la Chine, y étaient représentés. Les participants au sommet avaient pour principales préoccupations : la nécessité d’agir en vue d’une compréhension commune de l’IA de pointe (la rareté des travaux scientifiques évaluant les risques existentiels est soulignée), le fait de traiter des risques actuels et des risques extrêmes futurs, de progresser vers la normalisation et l’interopérabilité en IA, d’associer les entreprises à la mise en place de tests de sécurité.
Ce premier sommet a débouché sur une déclaration commune, la Bletchley Declaration, qui assure la description des risques potentiels de l’IA et propose de développer un réseau de chercheurs à ce sujet. Il a aussi conduit à un rapport commun sur l’état de la recherche sur les risques extrêmes posés par les modèles de fondation, dit State of Science Report et a appelé à la création de AI Safety Institutes, qui auront pour mission de renforcer la capacité du secteur public à mener des recherches sur la sécurité de l’IA et à effectuer des tests de sécurité avant et après la mise sur le marché des modèles.
La pérennisation de cette première initiative a également été actée, ce qui s’est traduit par l’organisation en 2024 d’un sommet sur la sécurité de l’IA en Corée du Sud en 2024 et la préparation d’un autre sommet en France au début de l’année 2025, sur lequel nous reviendrons.
Le soft power britannique passe par le fait de diffuser son modèle de régulation de l’IA à l’international, pour peser dans les instances multilatérales et sur l’édiction de standards internationaux.
En conclusion, l’approche britannique souple et pro-innovation doit contribuer à faire du Royaume-Uni « la place la plus attractive pour l’IA dans le monde ». Le gouvernement souhaite tirer profit du Brexit et de sa liberté réglementaire pour proposer un cadre plus souple que l’AI Act européen et attirer des capitaux étrangers.
Cette approche a des avantages (un parti pris pro-innovation, une souplesse et une adaptabilité aux évolutions des technologies, une connaissance fine de leurs secteurs par les régulateurs, etc.) mais aussi des limites (difficulté pour les régulateurs à exercer la charge qui leur sera confiée tant matériellement que techniquement, absence de cadre harmonisé entre les régulateurs et potentiels conflits d’interprétation, ce qui pourrait conduire à une sécurité et une prévisibilité moindre pour les entreprises).
De plus, pour rester une superpuissance de l’IA, le Royaume-Uni a encore des défis à relever, comme :
– une offre souveraine de GPU, avec l’annonce d’un investissement d’un milliard de livres dans le secteur des semi-conducteurs ;
– l’accès à la puissance de calcul, en 2022, le Royaume-Uni représentait 1,3 % des parts mondiales de capacités de calculs contre 2,46 % pour la France ;
– l’accès aux données, bien que les organismes publics, y compris le NHS, possèdent des données précieuses, celles-ci sont souvent mal organisées et difficiles d’accès ;
– un niveau d’investissement dans l’IA à accroître, étant actuellement largement inférieur à ceux des États-Unis et de la Chine.
Comme dans d’autres contextes nationaux, la législation britannique sur la propriété intellectuelle applicable à l’IA générative nécessitera des éclaircissements, qu’il s’agisse du régime des données utilisées pour entraîner les modèles, des droits de propriété du contenu produit à l’aide de l’IA générative ou, encore, des risques de violation d’un droit d’auteur.
g) Israël
L’industrie israélienne de l’IA générative progresse rapidement (un rapport place même l’écosystème de capital-risque de l’IA générative du pays au troisième rang mondial) en accord avec une stratégie nationale pour l’IA ambitieuse et un volet stratégique au sein de la politique de défense.
La volonté de protéger son secteur technologique (20 % du PIB israélien environ) a conduit Israël à refuser un encadrement strict de l’IA. Israël a donc choisi d’adopter une approche de régulation douce et de gouvernance de l’IA, basée sur les risques et spécifique à chaque secteur.
Il n’existe donc pas de lois ou de réglementations spécifiques qui régissent directement l’IA dans ce pays. Israël ne dispose pas non plus d’autorité de régulation de l’IA. Le ministère israélien de l’innovation, de la science et de la technologie (MIST) sert d’agence exécutive de la stratégie nationale d’IA et collabore étroitement avec le ministère israélien de la justice (MOJ). En 2022, le MIST et le MOJ ont publié un projet de document d’orientation sur l’IA. Après avoir mené des consultations publiques, les deux ministères ont publié un document d’orientation en décembre 2023 intitulé « Innovation responsable : la politique d’Israël en matière de réglementation et d’éthique de l’intelligence artificielle ». Ce document décrit l’approche du pays en matière de gouvernance et de politique de l’IA. L’innovation responsable est un terme qui reflète la volonté du pays de protéger et de favoriser son industrie technologique en pleine croissance tout en restant attaché à des principes non contraignants.
Le document d’orientation recommande aux régulateurs de formuler leurs politiques sur la base des principes de l’OCDE pour garantir la fiabilité de la technologie de l’IA. Israël a en effet officiellement approuvé les principes de l’OCDE en matière d’IA, et a fait de ces lignes directrices internationales une base pour les acteurs israéliens de l’IA. Cette approche vise à renforcer la croissance, le développement durable, l’innovation, le bien-être social et la responsabilité.
En outre, elle souligne l’importance du respect des droits fondamentaux et des intérêts publics, de la garantie de l’égalité, de la prévention des préjugés et du maintien de la transparence, de la clarté, de la fiabilité, de la résilience, de la sécurité et de la sûreté. En particulier, le document d’orientation préconise l’adoption d’une approche fondée sur les risques au moyen d’évaluations des risques menées par les régulateurs sectoriels concernés, conformément aux principes de l’OCDE.
Le document recommande également qu’Israël établisse des directives nationales pour atténuer les abus potentiels du secteur privé, tels que la discrimination, le manque de surveillance humaine, l’explicabilité insuffisante, la divulgation inadéquate, les problèmes de sécurité, les lacunes en matière de responsabilité et les violations de la vie privée.
Pour répondre à ces préoccupations, le document préconise d’éviter une législation horizontale de grande envergure et d’opérer plutôt dans le cadre de réglementations sectorielles spécifiques. Il appelle aussi à la création d’un centre de coordination des politiques d’IA sous l’égide du ministère de la justice, qui fonctionnerait comme un organe interministériel pour faciliter la coordination entre les différents départements et les agences concernées. Ce centre serait également chargé de conseiller les régulateurs, de faciliter le dialogue et le partage des connaissances avec le monde universitaire et l’industrie, et d’aider les régulateurs à identifier les applications et les défis de l’IA au sein des secteurs réglementés.
En conclusion, bien qu’aucune obligation spécifique ne soit actuellement imposée en Israël aux développeurs, aux déployeurs ou aux utilisateurs de systèmes d’IA, ces acteurs doivent se préparer à la mise en oeuvre d’éventuelles normes qui seraient en harmonie avec les principes de l’OCDE.
h) L’Arabie Saoudite
Le Royaume d’Arabie saoudite n’a pas encore adopté de cadre juridique pour la gouvernance de l’IA, préférant se concentrer sur la croissance et l’investissement. Il a cependant mis à jour ses lois sur le droit d’auteur et les données personnelles pour relever les défis posés par l’IA.
Le pays a établi une autorité spécialisée et a adopté des principes éthiques pour guider le développement de l’IA.
L’Autorité saoudienne de l’intelligence artificielle (SDAIA) est ainsi chargée de superviser les ambitions du pays en matière d’IA et de préparer de nouveaux cadres législatifs et réglementaires pour l’IA.
Les Principes d’éthique de l’IA de l’Arabie saoudite tentent de régir son secteur croissant de l’IA. Cependant, la portée juridique de ces lignes directrices n’est pas claire.
i) Les Émirats arabes unis (EAU)
Parmi tous les pays arabes, les Émirats arabes unis (EAU) jouent un rôle de premier plan dans le développement des technologies d’intelligence artificielle. Dès octobre 2017, le pays a clairement exprimé son ambition de construire son écosystème d’IA dans le cadre de sa stratégie nationale pour l’intelligence artificielle. L’objectif de cette stratégie est de mettre l’accent sur les moyens d’améliorer la compétitivité des EAU en matière d’IA dans la région et dans le monde. Une priorité de second rang consiste à garantir une gouvernance et une réglementation efficaces. Un Conseil de l’intelligence artificielle et de la blockchain a notamment été mis en place.
Avec un financement du conseil de recherche sur les technologies avancées du gouvernement d’Abou Dhabi, le pays a produit le LLM en open source Falcon 180B, du nom de l’oiseau national des Émirats. Lors du lancement de Falcon par l’Institut d’innovation technologique des EAU en septembre 2023, Hugging Face a salué son arrivée comme « le plus grand LLM disponible en libre accès, avec 180 milliards de paramètres ». La création de Falcon a marqué une étape importante dans la stratégie nationale des Émirats pour intégrer le club des leaders mondiaux de l’IA.
Privilégiant l’innovation et la compétitivité, les Émirats n’ont adopté ni loi ni réglementation spécifique de l’IA. Ils privilégient des « bacs à sable réglementaires » plutôt qu’un cadre juridique contraignant : cette stratégie favorise le développement technologique avec des tests en direct des technologies dans un environnement contrôlé sous la supervision directe d’un régulateur. Il n’est pas surprenant que cette approche favorable aux développeurs reçoive le soutien marqué d’entreprises d’IA comme OpenAI.
La gouvernance globale de l’IA est insuffisante en dépit des annonces répétées de nombreuses organisations internationales en la matière. Non seulement les propositions se multiplient de manière stérile car non coordonnée mais l’on assiste au creusement de la fracture numérique mondiale sous l’effet de l’IA, très inégalement distribuée sur notre planète, tant du point de vue de sa production que de son utilisation.
Outre leurs propres investigations, auditions, déplacements et questionnaires, les rapporteurs ont pu s’appuyer pour cette partie sur les travaux comparatifs de Florence G’sell, rencontrée à l’Université de Stanford.
Ses recherches montrent que plusieurs catégories d’actions internationales peuvent être distinguées :
– le fait de rédiger des traités internationaux ou des lignes directrices mondiales, comme le traité contraignant du Conseil de l’Europe, l’accord non contraignant de l’ONU appelé « Pacte numérique mondial » ou les recommandations de l’Unesco ;
– le soutien aux politiques nationales et internationales par des recommandations et des travaux d’experts, comme l’illustrent les contributions de l’OCDE et du Partenariat mondial sur l’intelligence artificielle ;
– les discussions internationales dans des forums diplomatiques restreints comme le G7, le G20, les BRICS ou le Conseil du commerce et des technologies UE-États-Unis (TTC) ;
– la coordination de l’action des États membres d’organisations supranationales en matière de régulation de l’IA comme l’illustrent les initiatives de l’UE ou de l’Union africaine ;
– ou encore le fait de convoquer des représentants des États et du monde économique autour d’une question spécifique, à l’instar des sommets sur la sécurité de l’IA.
Dès 2016, l’Organisation de coopération et de développement économiques (OCDE) a réuni un forum de prospective sur l’IA puis a organisé en 2017 une grande conférence sur l’IA (« L’IA. Machines intelligentes, politiques intelligentes »). En 2018 et 2019, elle s’est appuyée sur un groupe d’experts sur l’IA pour élaborer, en mai 2019, des principes de l’IA et des recommandations de l’OCDE pour les politiques publiques.
1. Les principes, les recommandations et la classification des systèmes
Adoptés en 2019 et amendés en 2024, les principes et les recommandations sur l’intelligence artificielle de l’OCDE fournissent des lignes directrices non contraignantes aux États membres et à toutes les parties prenantes dans le cadre d’une approche responsable pour une IA digne de confiance. Certaines des recommandations concernent spécifiquement la gouvernance de l’IA et les politiques publiques de l’IA à mettre en place au niveau national. Une mise à jour des principes a été effectuée en 2024.
Prendre des décisions d’encadrement de l’IA nécessite de savoir de quoi l’on parle : il faut pouvoir décrire ce que l’on souhaite exactement réguler. Ainsi, l’OCDE propose un cadre qui permet de classer les systèmes d’IA selon différentes dimensions aux stades de leur conception et de leur utilisation. Tous les pouvoirs publics devraient prendre en compte cet outil de classification ou une méthode similaire (tournée davantage vers la chaîne de valeur de l’IA par exemple) pour mettre en place des politiques publiques de régulation de l’IA.
L’OCDE fait valoir que tout modèle d’IA se décompose en quatre phases distinctes : le contexte (1), les données d’entrées (2), les modèles d’IA (3), les tâches demandées ainsi que les sorties de l’IA (4). Bien que ces phases soient distinctes, elles s’influencent mutuellement et ne peuvent pas être traitées de manière totalement indépendante.
Le contexte désigne l’environnement socio-économique dans lequel l’IA est déployée. Il désigne aussi bien l’utilisateur potentiel du modèle, que les parties prenantes à son développement, ou le secteur économique qu’il sert. De ce contexte dépendent les données et les valeurs d’entrées du modèle d’IA pour lesquelles il est important de connaître la nature mais également la façon dont elles sont collectées, ou dont elles sont amenées à évoluer, s’il s’agit de données dynamiques. De ces données récoltées dépend le modèle d’IA, qui est lui-même, un critère de classification. Le modèle peut être de type symbolique, donc basé sur une série de règles logiques, ou connexionniste et donc appuyé sur des calculs de type statistique. S’il est connexionniste, le modèle peut être soumis à un apprentissage supervisé ou semi-supervisé par exemple. Enfin, selon le type de modèle, les sorties ne sont pas les mêmes et il est évidemment important d’évaluer les modèles à la lumière de leur production et des tâches qui leur sont demandées.
Par exemple, une IA appliquée au secteur des banques et assurances peut être considérée comme particulièrement sensible car elle prend place dans un contexte (1) pouvant influencer de façon importante la vie des personnes qu’elle concerne. Elle prendrait en entrée des données personnelles, relevés de compte ou données de santé par exemple (2). Selon que le modèle utilisé est symbolique ou connexionniste (3), on n’a pas la même possibilité d’expliquer les choix réalisés en sortie par le système d’IA (4), ce qui peut représenter une injustice pour le client concerné.
L’OCDE pose cinq principes généralistes que doivent respecter les systèmes d’IA tout au long de leur cycle de vie et qui concernent l’ensemble des acteurs concernés par l’IA. Elle formule aussi cinq recommandations spécifiques à destination des décideurs politiques.
Les principes généralistes à destination de tous les acteurs de l’IA sont conçus à partir des valeurs morales nécessaires au développement d’une IA saine. Ces principes sont : « Croissance inclusive, développement durable et bien-être » (1.1), « Droits de l’homme, vie privée, équité » (1.2), « Transparence, explicabilité » (1.3), « Robustesse, sécurité, sûreté » (1.4) et « Responsabilité » (1.5). Ces principes font qu’une intelligence artificielle doit être dédiée à la prospérité et être bénéfique à l’humanité et à la planète (1.1), dans le respect des droits de l’homme, de la dignité humaine, de la vie privée et sans induire de discriminations (1.2). Ses sorties doivent être explicables au mieux et de la façon la plus transparente possible (1.3) tout en protégeant les données des utilisateurs du modèle ou des personnes dont les données ont servi d’entraînement au modèle, la sécurité et la sûreté du système doivent être garanties (1.4). Enfin, les individus et organisations qui déploient des systèmes d’IA doivent toujours être responsables du fonctionnement, donc des résultats de ces derniers et être capables d’en rendre compte (1.5).
Les cinq recommandations pour les décideurs politiques doivent permettre à ceux-ci d’anticiper les transformations liées au développement de l’IA. L’organisation recommande ainsi : un investissement dans la recherche et le développement de l’IA (2.1), l’encouragement d’un écosystème numérique pour l’IA (2.2), la fourniture d’un environnement de politiques publiques propices à l’IA (2.3), la construction et la préparation de capacités humaines pour la transformation du marché du travail (2.4) et la coopération internationale pour une IA de confiance (2.5).
Plus concrètement, cela signifie que les gouvernements devraient envisager des investissements de long terme dans la recherche et le développement d’IA mais également encourager la recherche publique comme la recherche privée, et ce, dans des domaines techniques mais également juridiques ou sociétaux, y compris à travers des investissements dans des systèmes ouverts dits open source (2.1). Les gouvernants devraient également encourager la création d’un écosystème permettant de faciliter le partage de technologies ou d’infrastructures entre les acteurs des systèmes d’IA de confiance (2.2). Un environnement de politiques publiques propices devrait également être construit, permettant de passer de la recherche et développement aux produits en passant, par exemple, par des mécanismes d’expérimentation de type bac à sable (2.3). Il faut également préparer la transition du marché du travail impliquée par l’IA en travaillant avec les parties prenantes à ce changement et en promouvant le dialogue social durant la mise en place de l’IA au travail (2.4). Enfin, plutôt qu’un travail strictement national, la gouvernance de l’IA devrait être le fruit de coopérations internationales permettant le partage d’informations ou le développement de normes internationales (2.5).
Le système de classification proposé par l’OCDE prend en compte l’ensemble du cycle de vie du modèle d’IA et permet de définir précisément ce qu’est un système d’IA et d’en donner des limites claires. Couplé à des principes éthiques également définis, il offre des ressources très utiles pour encadrer l’IA, surtout que l’OCDE y ajoute des recommandations pour le contenu des politiques publiques à mettre en place. L’organisation a aussi proposé de définir des métriques d’analyse et des outils pour corriger les problèmes pouvant subvenir. L’objectif est de maximiser, grâce à ces outils, le respect des principes éthiques par l’ensemble des parties prenantes, dont les gouvernants, tout au long du cycle de conception et d’utilisation de l’IA.
2. La méthodologie des métriques
L’OCDE a commencé par recenser un ensemble de métriques d’analyse et d’outils provenant d’organismes publics ou privés, permettant d’évaluer et de corriger d’éventuels défauts présents dans l’une des quatre phases des systèmes d’IA mentionnées ci-dessus. L’organisation a répertorié des méthodologies pour 104 métriques et 125 outils techniques de correction des systèmes d’IA.
L’utilisation d’une métrique d’évaluation dépend du type de modèle utilisé, le Word Error Rate ne peut s’appliquer qu’aux modèles de reconnaissance de discours par exemple. Elle dépend également de l’objectif évalué lors du passage du test. L’OCDE en répertorie huit, fondés sur les principes éthiques définis dans son cadre d’analyse. Certaines métriques relèvent de plusieurs principes, mais certains principes n’ont aucune métrique : responsabilité (aucune métrique disponible), équité (20 métriques), bien-être humain (aucune métrique), performance (78 métriques), gouvernance des données et de la vie privée (1 métrique), robustesse et sécurité numérique (7 métriques), sûreté (1 métrique) et transparence et explicabilité (11 métriques). On peut remarquer une répartition inégale des métriques selon les catégories, la performance des modèles possédant par exemple bien plus de métriques que les autres catégories.
En plus de ces métriques, le site de l’OCDE propose des outils d’écoute sociale relatifs à l’IA, par exemple celui concernant les tweets sur X (ex-Twitter) mentionnant l’intelligence artificielle.
Moyenne mensuelle du nombre de tweets sur X (ex-Twitter) mentionnant l’intelligence artificielle en France
Légende :
– en abscisse, la date
– en ordonnée, la moyenne mobile sur 30 jours du nombre de tweets mentionnant l’IA
Source : OECD.AI
On trouve également une mesure du nombre d’incidents concernant l’IA (AIM) qui est un outil d’écoute sociale puisqu’ il s’appuie sur le traitement automatique d’articles de presse dans le monde, et permet de voir quels sont les moments d’engouement médiatique autour de la notion d’intelligence artificielle. La mesure des incidents peut se décliner en fonction de la nature de l’incident (c’est-à-dire en fonction du principe éthique que l’IA n’a pas respecté), mais également de sa sévérité (menace non physique, danger, blessure ou mort), du type de dommage causé (physique, psychologique, etc.) et de la partie prenante victime de l’incident (gouvernement, consommateur, travailleur, minorité, etc.).
Le cadre de travail de l’IA de l’OCDE permet donc de définir l’IA au-delà de sa simple définition technique : la mise en place de politiques publiques selon ses recommandations exige par exemple de s’intéresser aux relations entre l’IA et son contexte ; le contexte influence les données et les résultats influencent l’environnement). Cette définition sociotechnique concerne un grand nombre de parties prenantes lors de la conception et l’utilisation de modèles d’IA.
Toutes les parties prenantes sont concernées par des enjeux éthiques majeurs liés à l’IA : les systèmes d’IA doivent être bénéfiques pour l’homme et son environnement, ils doivent respecter la dignité humaine et faire en sorte qu’aucun biais ne puisse nuire aux utilisateurs. Les données d’entraînement ainsi que les données des utilisateurs doivent être protégées de façon robuste et les organisations doivent toujours être responsables des produits d’un système d’IA. Pour cela, les décideurs publics doivent mettre en place des initiatives qui permettent d’encourager la recherche et développement, ainsi que de créer un écosystème sain. Les décisions doivent être prises en accord avec les multiples parties prenantes lors de la création des systèmes d’IA comme pendant leur phase de fonctionnement, qu’il s’agisse du secteur public comme du secteur privé. La gouvernance mondiale de l’IA doit être mise en place pour permettre la création de normes internationales ainsi qu’un partage plus vaste des bonnes pratiques.
Des métriques et outils sont déjà à disposition pour évaluer et corriger les défauts des systèmes d’IA, toutefois comme il a été vu, tous les principes ne disposent pas de métriques permettant leur évaluation : la performance est clairement le critère le plus évalué alors que les aspects éthiques ou la responsabilité sont difficilement voire pas du tout mesurées. En conclusion, à côté de l’évaluation des modèles eux-mêmes, l’écoute sociale peut faire partie des outils techniques qui permettent d’observer l’environnement de l’IA, notamment le rapport de la société aux technologies.
3. L’Observatoire des politiques publiques de l’IA
L’OCDE a créé un Observatoire des politiques publiques de l’IA pour aider les décideurs politiques et les experts en IA à travers un centre de ressources complet sur les politiques et les normes applicables à l’IA, tout en promouvant les lignes directrices de l’OCDE puisqu’il surveille aussi la manière dont les pays respectent et mettent en oeuvre les principes et les recommandations politiques de l’organisation.
L’évaluation biennale conduite par l’Observatoire, intitulée « L’état de mise en oeuvre des principes de l’OCDE en matière d’IA », indique qu’en 2024 plus de 50 pays avaient mis en oeuvre des stratégies nationales en matière d’IA, dont beaucoup font directement référence aux principes de l’OCDE.
Sur les 46 adhérents aux principes de l’OCDE en matière d’IA, 41 avaient mis en place une stratégie nationale et trois étaient en train d’en élaborer une. Le rapport indique qu’en mai 2024, plus de 1 020 programmes d’action avaient été initiés dans 70 pays membres et non membres, ce qui témoigne de l’attention accrue portée à la gouvernance de l’IA depuis 2019.
Le site de l’Observatoire des politiques de l’IA de l’OCDE propose également un référentiel en temps réel qui suit les paysages réglementaires de l’IA de 69 pays différents. Il fournit également des outils pour l’audit des systèmes d’IA et un Global AI Incident Monitor (AIM).
Pour soutenir davantage l’AIM et les travaux de l’OCDE visant à recueillir des rapports sur les incidents liés à l’IA, l’Observatoire des politiques de l’IA a publié un rapport sur la définition des incidents liés à l’IA et des termes associés qui propose des distinctions importantes entre les incidents liés à l’IA et les dangers de l’IA.
LE CADRE MULTILATÉRAL EN CONSTRUCTION
1. La contribution multiforme mais encore inachevée de l’Organisation des Nations unies (ONU)
L’Organisation des Nations unies (ONU) souhaite s’associer avec l’OCDE pour avancer sur le chemin d’une régulation mondiale de l’IA, même si elle a semblé adopter une position prudente quant à la gouvernance globale de l’IA jusqu’ici, dans le cadre de son mandat en faveur de la paix et de la sécurité dans le monde.
Il s’agit surtout pour elle de trouver des consensus au sein de la communauté internationale et de voter des résolutions qui posent un cadre non contraignant en vue du respect de ces consensus, sans aller jusqu’à une régulation réelle de l’IA par le droit international.
Lors du déplacement des rapporteurs aux États-Unis, la représentante du bureau de liaison ONU-Unesco a confirmé que les institutions onusiennes n’en sont pas encore au stade de la construction effective d’une organisation internationale pour la gouvernance de l’IA. Une avancée importante vient cependant d’être faite très récemment avec le Pacte numérique mondial de septembre 2024.
Avant cela, l’IA n’avait pas été écartée du champ de travail de l’ONU puisque l’on dénombrait environ 300 projets en lien avec l’IA dans l’ensemble de l’ONU et de ses institutions.
La première de ces contributions est celle de l’Organe consultatif de haut niveau sur l’intelligence artificielle (High-Level Advisory Body on AI) mis en place par le Secrétaire général des Nations unies en octobre 2023.
Le rapport provisoire de ce groupe multipartite a été publié en décembre 2023 sous le titre « Interim Report : Governing AI for Humanity », suivi d’un rapport définitif en septembre 2024 : « Governing AI for Humanity ».
Ce dernier a été rendu public à l’occasion du Sommet sur le Futur qui s’est tenu les 22 et 23 septembre 2024 au siège de l’ONU à New York en présence de plus de 130 chefs d’État et de gouvernement et qui a surtout été l’occasion d’adopter un Pacte numérique mondial et d’annoncer le lancement d’un travail en commun entre l’ONU et l’OCDE afin de renforcer la gouvernance mondiale de l’IA.
Un autre aspect est celui de la place accordée aux droits de l’homme. En novembre 2023, le Haut-Commissaire des Nations unies aux droits de l’homme, Volker Türk, appelait ainsi à porter la plus grande attention aux risques liés à l’IA, en insistant sur son impact en matière de droits humains. Dans cette déclaration, il proposait des évaluations des modèles d’IA dans les domaines dans lesquels les technologies pourraient avoir des effets significatifs, affirmant que tout projet de gouvernance mondiale de l’IA devrait prendre en compte les droits de l’homme.
L’Assemblée générale des Nations unies a apporté sa contribution à la discussion internationale avec le vote de plusieurs résolutions appelant à la coopération pour garantir la sécurité des systèmes d’IA.
Le 21 mars 2024, elle a adopté une première résolution, soutenue par plus de 120 États membres, dont la France et surtout les États-Unis, à la tête de l’initiative. La résolution vise à « saisir les possibilités offertes par des systèmes d’intelligence artificielle sûrs, sécurisés et dignes de confiance pour le développement durable ».
Non contraignante, elle préconise une approche de régulation axée sur la sécurité, le respect des droits de la personne et des libertés fondamentales et l’inclusivité. Elle souligne l’importance de diffuser partout dans le monde les capacités de l’IA, en particulier dans les pays en développement.
Elle affirme également que les droits de l’homme doivent être respectés tout au long de la chaîne de valeur de l’IA, en ligne et hors ligne, demandant à tous les États membres de s’abstenir ou de cesser d’utiliser des systèmes d’IA contraires au droit international des droits de l’homme, ou qui présentent un risque pour ces derniers. L’Assemblée générale considère que les systèmes d’IA sont des outils qui peuvent être mobilisés par les États pour répondre aux objectifs de développement durable 2030.
Dans le même temps, elle souligne les risques potentiels des technologies d’IA dans les domaines de la vie privée, des données personnelles ou encore du droit d’auteur, ainsi que les risques de biais induits par l’IA. Aussi, elle invite à prendre des mesures d’évaluation et de gouvernance des modèles, en promouvant des modèles sûrs, sécurisés et dignes de confiance.
L’Assemblée générale des Nations unies a poursuivi sa réflexion avec le vote le 1er juillet 2024 d’une autre résolution visant à « intensifier la coopération internationale en matière de renforcement des capacités dans le domaine de l’intelligence artificielle ».
Initiée par la Chine, cette résolution poursuit un objectif spécifique de solidarité internationale afin de permettre aux États membres de combler leurs lacunes éventuelles en termes de développement de l’IA. Elle vise à favoriser une coopération étroite en matière d’IA en encourageant davantage le partage de connaissances, les transferts de technologie, la formation et des recherches collaboratives au sein de la communauté internationale.
La résolution demande aux États membres de mettre en place autant que possible des plans de renforcement de leurs capacités souveraines dans le cadre de leurs stratégies nationales relatives à l’IA.
Sur un autre aspect, en novembre 2023, la commission sur le désarmement et la sécurité internationale de l’Assemblée générale des Nations unies a adopté une résolution contre les armes létales autonomes.
Le Pacte numérique mondial, adopté en septembre 2024 par les participants au Sommet sur le Futur, vingt ans après le Sommet mondial des Nations unies sur la société de l’information, trace une feuille de route pour une coopération numérique à l’échelle mondiale poursuivant à la fois l’objectif d’exploiter l’immense potentiel des technologies numériques et celui de combler les fractures numériques existantes.
Non contraignant, ce Pacte numérique mondial propose un premier cadre global préparatoire à une gouvernance mondiale des technologies numériques et de l’intelligence artificielle. Il en définit les objectifs, les principes, les engagements et les actions permettant de développer un avenir numérique ouvert, libre et sûr pour tous, en soulignant les avantages que les technologies numériques apportent à l’humanité.
Le Pacte, qui a bénéficié de l’aide de l’UE et pour lequel la Commission européenne s’est fortement investie, se déclinera à travers :
– un comité scientifique international indépendant sur l’IA pour promouvoir la compréhension scientifique (la question du rôle futur de l’Organe consultatif de haut niveau sur l’intelligence artificielle au sein de l’ONU est donc posée) ;
– un dialogue mondial sur la gouvernance de l’IA impliquant les gouvernements des États membres et toutes les parties prenantes concernées, sera lancé en marge des conférences et réunions pertinentes des Nations unies ;
– l’engagement des États membres à prendre plusieurs mesures d’ici 2030, telles que le développement de mécanismes de financement et d’incitations pour connecter les 2,6 milliards de personnes ne bénéficiant pas d’Internet, l’établissement de garanties pour prévenir et traiter tout impact négatif sur les droits de l’homme découlant de l’utilisation des technologies numériques émergentes et la fourniture et la facilitation de l’accès à des informations scientifiques indépendantes pour lutter contre la désinformation.
2. Le travail spécifique de l’Organisation des Nations unies pour l’éducation, la science et la culture (Unesco)
Dans les domaines de la science, de la culture et de l’innovation, qui sont le coeur de ses compétences, l’Unesco, a initié plusieurs réflexions en matière d’intelligence artificielle. Pour rester dans son champ de compétences, l’Unesco a principalement proposé la définition de règles éthiques, d’application large. Ainsi, Gabriela Ramos, sous-directrice générale pour les sciences sociales et humaines de l’Unesco affirme : « Dans aucun autre domaine, la boussole éthique n’est plus pertinente que dans celui de l’intelligence artificielle ».
Un travail préliminaire a été réalisé en 2019 par sa Commission mondiale d’éthique des connaissances scientifiques et des technologies (COMEST).
Puis l’Unesco a publié le 23 novembre 2021 ses recommandations éthiques en matière d’intelligence artificielle, adoptées par 193 pays. Dix principes éthiques, non contraignants, assez proches de ceux préconisés par l’ONU, ciblent les systèmes d’IA par rapport aux domaines centraux de l’Unesco : éducation, science, culture, communication et information.
Pour permettre la mise en oeuvre concrète de ces recommandations éthiques, une méthodologie a été mise à la disposition des État (appelée « méthode d’évaluation de l’état de préparation ») et une autre a été préparée spécifiquement pour les entreprises (appelée « évaluation de l’IA éthique »). Un accord a été signé le 5 février 2024 lors du deuxième Forum mondial de l’Unesco sur l’IA par huit entreprises du secteur numérique et Audrey Azoulay, directrice générale de l’Unesco
Dans le cadre de la Semaine de l’apprentissage numérique qui s’est tenue à Paris en septembre 2023, l’Unesco a publié un Guide pour l’IA générative dans l’éducation et la recherche, qui présente les technologies d’IA générative et les différents modèles actuellement disponibles.
Il propose des recommandations pour encadrer ces technologies à la lumière de principes éthiques en promouvant l’inclusion et l’équité. Il met l’accent sur une approche centrée sur l’humain, en prônant surtout une vigilance sur les usages de l’IA dans les contextes éducatifs, ces usages devant être éthiques, sûrs, justes et dotés de sens.
Il propose des mesures pour intégrer de manière responsable l’IA dans les activités d’enseignement, d’apprentissage et de recherche, notamment avec une explication pédagogique des technologies d’IA générative, une présentation de leurs enjeux éthiques et politiques et de leurs perspectives d’encadrement.
Le rapport fournit des exemples d’usages de l’IA générative apportant des bénéfices pour la pensée critique ainsi que pour la créativité dans l’éducation et la recherche, tout en en atténuant les risques lors de la conception de programmes, dans l’enseignement et les activités d’apprentissage.
À la suite de ces recommandations, l’Unesco a créé en février 2024, en partenariat avec d’autres institutions comme l’Institut Alan Turing ou l’Union internationale des télécommunications (UIT), un Observatoire international de l’éthique et de la gouvernance de l’intelligence artificielle (en anglais Global AI Ethics and Governance Observatory). Sur la base des recommandations de 2021, l’observatoire a pour objectif de fournir aux parties prenantes des ressources pour discuter des dilemmes éthiques liés à l’IA qui se présentent à eux, ainsi que de leurs implications sociétales.
3. Les Principes pour l’IA du G20
En relation avec l’ONU et l’Unesco, le G20 – qui représente 85 % de l’économie mondiale et 80 % de la population mondiale – a adopté, lors du sommet d’Osaka de 2019, des « Principes pour l’IA », qui reprennent les priorités fixées par l’OCDE. Depuis, le G20 a mis l’intelligence artificielle à l’ordre du jour de chacune de ses rencontres.
Le sommet du G20 de Rio de Janeiro des 18 et 19 novembre 2024, est l’occasion de poursuivre la discussion sur les principes de l’IA et sur les moyens par lesquels le G20 peut contribuer à la réflexion internationale sur l’IA, en intégrant la dimension du développement, de la fracture numérique mondiale et de la justice sociale, à laquelle le Brésil est attaché.
Le groupe de travail sur l’économie numérique du G20 a d’ailleurs organisé en avril 2024 une conférence sur « l’intelligence artificielle pour le développement durable et la réduction des inégalités ».
1. Le G7 et son « processus d’Hiroshima »
Le G7 a lancé en mai 2023 un dispositif appelé « processus d’Hiroshima » qui vise à définir de grands principes pour régir l’utilisation de l’intelligence artificielle générative. Il s’agit d’un cadre d’action non contraignant fondé sur les principes suivants : promouvoir une IA sûre et digne de confiance ; fournir des orientations aux organisations qui développent et utilisent les systèmes d’IA ; analyser les possibilités et les défis que représente l’IA ; et promouvoir la coopération pour le développement d’outils et de pratiques en matière d’IA.
Cinq mois plus tard, le 30 octobre 2023, éclairé par un rapport commandé à l’OCDE sur ce processus d’Hiroshima, le G7 a publié « Les principes directeurs internationaux du processus d’Hiroshima pour les organisations développant des systèmes d’IA avancés » et « Le code de conduite international du processus d’Hiroshima pour les organisations développant des systèmes d’IA avancés » et annoncé des projets de recherche conjoints sur l’IA générative avec le Partenariat mondial sur l’intelligence artificielle et l’OCDE.
Les principes directeurs et le code de conduite forment – avec le rapport commandé à l’OCDE et ces projets de recherche conjoints sur l’IA générative – le cadre du processus d’Hiroshima. Ils abordent la « conception, le développement, le déploiement et l’utilisation de systèmes d’IA avancés » et intègrent un large éventail de principes internationaux existants, offrant un ensemble de lignes directrices plus détaillées que les principes de l’OCDE auxquels ils se réfèrent explicitement.
L’approche est fondée sur les risques tout au long du cycle de vie de l’IA, en commençant par des évaluations des risques avant le déploiement et des stratégies d’atténuation. Les développeurs et les déployeurs de modèles et de systèmes d’IA sont ainsi tenus de mettre en oeuvre des procédures de gestion des risques, ainsi que des contrôles de sécurité robustes, y compris sous la forme d’exercices internes de red teaming. L’importance d’une surveillance, d’un signalement et d’une atténuation continus des abus et des incidents est soulignée. En outre, les principes et le code de conduite identifient les domaines prioritaires de la recherche et du développement de l’IA, tels que l’authentification du contenu, la protection des données personnelles et l’établissement de normes techniques.
Les deux documents se réfèrent aux mêmes principes mais ne sont pas destinés aux mêmes publics : les principes directeurs s’adressent à toutes les parties prenantes tandis que le code de conduite est d’abord destiné aux entreprises développant ou déployant des systèmes d’IA.
Le cadre du processus d’Hiroshima est non contraignant et repose sur la participation volontaire des États et des entreprises. De nombreuses entreprises ont manifesté leur intérêt mais pas encore les grandes sociétés américaines de type MAAAM, ou comme Nvidia et IBM. Parmi les entreprises développant des modèles de pointe, seul Anthropic s’est engagé à mettre en oeuvre le code de conduite du processus d’Hiroshima.
Certains observateurs ont dénoncé un cadre trop long sur les bonnes intentions et insuffisamment détaillé, concret et opérationnel. Le Président américain s’est pourtant en partie inspiré de ce cadre pour son Executive Order de 2023, rédigé avec l’appui du Nist. La présidente de la Commission européenne a, de son côté, estimé que le code de conduite était complémentaire à l’AI Act. En juin 2024, le G7 a décidé de préparer un outil de suivi de mise en oeuvre du code de conduite.
Compte tenu de l’importance du sujet, à l’occasion de la réunion des ministres de l’industrie, de la technologie et du numérique du G7 les 14 et 15 mars 2024 consacrée à la future réglementation mondiale de l’IA, il a été décidé d’ouvrir les débats à différentes organisations et plusieurs autres pays : l’OCDE, le Programme des Nations unies pour le développement (PNUD), l’Unesco, l’Union internationale des télécommunications (UIT) et l’Envoyé du Secrétaire général des Nations unies pour la technologie ainsi que le Brésil, la Corée du Sud, l’Ukraine et les Émirats arabes unis ont été invités à se joindre à la conférence. Les participants sont convenus de mettre à jour les Principes directeurs et le Code de conduite du processus d’Hiroshima en fonction des nouveaux développements de l’IA.
Le 2 mai 2024, un an après le lancement du processus d’IA d’Hiroshima, le Premier ministre japonais Kishida Fumio a annoncé la création du club des amis du processus de l’IA d’Hiroshima, un groupe de 49 pays qui soutiennent l’esprit du cadre et ses lignes directrices volontaires.
En conclusion, même si la mise en oeuvre de ce cadre reste incertaine, elle est néanmoins devenue un signe important de la mobilisation internationale en faveur de la gouvernance mondiale de l’IA.
2. L’expertise du Partenariat mondial sur l’intelligence artificielle (PMIA) ou Global partnership on artificial intelligence (GPAI)
Le Partenariat mondial sur l’intelligence artificielle (PMIA ou, en anglais, Global partnership on artificial intelligence ou GPAI) est une initiative internationale proposée en 2018 au sommet du G7 par la France et le Canada.
Ce partenariat, qui s’inspirait du Groupe d’experts intergouvernemental sur l’évolution du climat (GIEC ou en anglais Intergovernmental Panel on Climate Change ou IPCC), est officiellement fondé en 2020 et compte aujourd’hui vingt-neuf membres.
Il vise à promouvoir une IA responsable respectueuse des droits de l’homme et de la démocratie. Le partenariat est organisé autour de quatre thèmes : IA responsable et gouvernance de la donnée, basés à Montréal ; innovation et commercialisation, et futur du travail à Paris.
Le secrétariat du PMIA est assuré par l’OCDE, dont le siège est à Paris. Ce partenariat donne lieu à des réunions annuelles et à la publication d’un rapport annuel sous l’égide de son groupe d’experts (le GIEC du PMIA ou GPAI IPCC a ainsi pris le nom de GPAI MEG pour Multi-stakeholders Experts Group).
En 2024, le PMIA a lancé un partenariat avec l’OCDE et son prochain sommet qui se tiendra à Belgrade en Serbie en décembre 2024 devrait réunir 44 pays et l’OCDE ainsi que des entreprises, des organisations internationales et des chercheurs.
3. Le Conseil du commerce et des technologies (CCT) UE-États-Unis
Le Conseil du commerce et des technologies (CCT) UE-États-Unis a été créé en 2021 pour encourager le commerce bilatéral et réduire l’écart entre la régulation américaine souvent non contraignante et la législation européenne, souvent ambitieuse, comme l’est celle de l’AI Act par exemple. L’UE est le premier marché d’exportation des États-Unis et les États-Unis sont le 2e plus grand importateur de produits européens. Cette économie transatlantique pèse plus de 1 100 milliards de dollars et justifie la recherche de principes et de normes harmonisés, autour de valeurs partagées (comme la protection des données personnelles ou les usages éthiques de l’IA). Depuis 2021, des réunions ont lieu régulièrement (sept à ce jour) conduisant l’UE et les États-Unis à mettre en place différentes initiatives.
Après une feuille de route conjointe sur les outils d’évaluation et de mesure pour une IA et une gestion des risques dignes de confiance adoptée en 2022, le CCT a mis en place trois groupes de travail pour avancer sur la voie de trois projets de collaboration en vue de faire converger les politiques en matière de risques et de créer des outils identiques et appropriés.
L’objectif est de créer une taxonomie et une liste de termes communs, de développer des outils techniques (dont des métriques et des méthodologies de mesure), des normes et des standards internationaux et de surveiller et mesurer les risques existants et les risques émergents liés à l’IA. En avril 2024, afin d’avancer plus vite sur la sécurité de l’IA, les normes et les usages éthiques, un nouveau dialogue collaboratif est créé par le CCT entre le EU AI Office et le US AI Safety Institute.
Trois autres initiatives peuvent être mentionnées : des recherches sur les technologies améliorant la protection de la vie privée (depuis 2022) ; un rapport sur l’impact de l’IA sur l’avenir des mains-d’oeuvre américaines et européennes (publié le 5 décembre 2022) suivi d’une Talent for Growth Tasfkforce chargée de l’amélioration de l’offre de formation permanente et de la diversification des pratiques de recrutement ; la préparation d’un code de conduite sur l’IA à destination des entreprises (mai 2023), abandonnée au motif que le processus d’Hiroshima du G7 poursuit le même objectif (ce travail du G7 a bien abouti le 30 octobre 2023).
D. LES INITIATIVES NON OCCIDENTALES
1. La Proposition chinoise de gouvernance mondiale de l’IA
En octobre 2023, le président Xi Jinping a présenté une initiative pour la gouvernance mondiale de l’IA témoignant de l’effort stratégique de la Chine pour construire et infléchir la future gouvernance mondiale de l’intelligence artificielle.
Cette initiative souligne l’engagement de la Chine à favoriser une gouvernance équitable de ces technologies par la coopération internationale en préconisant une approche équilibrée qui tienne compte à la fois des opportunités et des risques de l’IA. Elle se distingue par l’importance qu’elle accorde à la collaboration internationale en soulignant la nécessité de veiller à ce que les pays en développement aient une voix significative dans la gouvernance mondiale de l’IA, permettant à toutes les nations, quels que soient leur statut économique ou leur système politique, de participer au développement et à la supervision de l’IA. L’Initiative s’oppose ainsi aux monopoles technologiques et promeut la coopération mondiale pour empêcher l’utilisation abusive des technologies de l’IA.
2. Le travail des BRICS
Les BRICS représentent plus de la moitié de la population mondiale et plus du quart de la richesse mondiale. Composé de cinq pays (Brésil, Russie, Inde et Chine en 2009, rejoints par l’Afrique du Sud en 2011), le groupe s’est étendu le 1er janvier 2024 à l’Égypte, à l’Iran, aux Émirats arabes unis et à l’Éthiopie, et une vingtaine d’autres pays ont demandé leur adhésion.
Depuis 2015, les BRICS ont jeté les bases de leur coopération en matière d’IA dans un « Memorandum of Understanding on Science, Technology, and Innovation », y soulignant que les technologies de l’information et des communications étaient un domaine essentiel de coopération. Dans leur déclaration commune de 2017, ces pays ont pour la première fois explicitement mentionné l’IA et en ont fait un domaine dans lequel ils devraient renforcer leurs efforts de coopération. Depuis, l’IA est régulièrement évoquée lors des sommets annuels et des rencontres ministérielles de l’organisation.
Une nouvelle étape a été franchie lors du sommet de Johannesburg en 2023, avec l’annonce par le président chinois Xi Jingping de la formation d’un Groupe d’étude sur l’IA sous l’égide de l’Institut des BRICS pour les réseaux du futur. Il s’agit à la fois de surveiller les avancées technologiques en matière d’IA, de favoriser l’innovation et d’établir un cadre international solide pour la gouvernance de l’IA. Le président Xi Jingping a annoncé que le groupe élaborerait des cadres et des normes de gouvernance de l’IA bénéficiant d’un large consensus. D’autres initiatives sur l’IA sont en cours au sein des BRICS, la Nouvelle Banque de Développement basée à Shanghai dirigée par l’ancienne présidente du Brésil Dilma Rousseff, dont l’Algérie est également membre, s’est par exemple dotée d’un groupe de travail sur l’économie numérique et les investissements dans les applications d’IA.
3. La stratégie de l’Union africaine
Les 55 États membres de l’Union africaine ont lancé, en 2013, « l’Agenda 2063 », un plan de développement de l’Afrique pour atteindre un développement socio-économique inclusif et durable en 50 ans.
L’Agence de développement de l’Union africaine dans le cadre du Nouveau Partenariat pour le développement de l’Afrique (AUDA-NEPAD), a publié le 29 février 2024, lors de la conférence « AI Dialogue » un livre blanc intitulé « Régulation et adoption responsable de l’IA en Afrique vers la réalisation de l’Agenda 2063 de l’Union africaine », élaboré pendant deux ans par un groupe de haut niveau sur les technologies émergentes (African Union’s High-Level Panel on Emerging Technologies ou APET).
En s’inspirant des lignes directrices de l’Unesco, le document exhorte toute future stratégie de l’Union africaine en matière d’IA à intégrer des principes éthiques et demande aux pays africains de mettre en oeuvre des stratégies nationales d’IA responsables en mettant l’accent sur des outils juridiques qui renforceront les valeurs d’équité, de sécurité, de confidentialité et de sûreté. Cependant, il n’aborde pas directement les modalités de gouvernance ni le détail des défis réglementaires et juridiques spécifiques de l’IA générative.
En février 2024, lors d’une réunion du Conseil exécutif de l’Union africaine (44e session), la Commission de l’Union africaine a appelé à une stratégie continentale pour l’IA, avec une feuille de route complète permettant aux nations africaines de développer de manière responsable les technologies d’IA. Un groupe de travail a été chargé de développer cette stratégie continentale en s’appuyant sur le livre blanc de l’AUDA-NEPAD. Le Comité technique de la communication et des technologies de l’information de l’Union africaine lors de sa réunion de juin 2024 a adopté à l’unanimité la stratégie continentale pour l’IA de l’Union africaine ainsi que le Pacte numérique africain, document distinct détaillant la stratégie de l’Afrique pour gérer son avenir numérique et promouvoir le progrès sociétal global.
Le Conseil exécutif de l’Union africaine a formellement adopté ces documents lors de sa 45e session qui s’est tenue à Accra en juillet 2024.
La commissaire aux infrastructures, à l’énergie et à la numérisation de l’Union africaine, Amani Abou-Zeid a déclaré qu’ils « fourniront des orientations sur l’utilisation de la technologie pour trouver des solutions aux défis de l’Afrique, aideront à accélérer de nombreux projets et programmes, et protégeront contre l’utilisation non éthique de la technologie : la technologie doit nous aider à préserver notre identité, nos langues et nos cultures, et nous être utile plutôt que de nous nuire ». Il s’agit aussi de créer plus globalement un environnement favorable au développement et à l’utilisation des technologies numériques et d’aider les gouvernements des différents États membres à élaborer leurs politiques en matière d’IA et de régulation du secteur numérique.
1. La Convention-cadre sur l’IA du Conseil de l’Europe
Avec ses 48 États membres et riche de ses plus de 220 conventions internationales, le Conseil de l’Europe a préparé depuis la fin de l’année 2019 à travers sa commission spéciale sur l’IA une Convention-cadre sur l’intelligence artificielle et les droits de l’homme, la démocratie et l’État de droit, qui a été adoptée le 17 mai 2024. Un rapport explicatif a été joint au texte.
Il s’agit du premier traité international juridiquement contraignant visant à garantir une utilisation des systèmes d’intelligence artificielle pleinement conforme aux droits humains, à la démocratie et à l’État de droit. Il nécessitera cependant d’être régulièrement ratifié par chacun des États qui auront décidé de le signer.
Ce traité international qui vise à garantir une IA respectueuse des droits fondamentaux a été ouvert à la signature le 5 septembre 2024, lors d’une conférence des ministres de la justice des États membres du Conseil de l’Europe organisée à Vilnius. À ce stade, il a été signé par Andorre, la Géorgie, l’Islande, la Norvège, la République de Moldova, Saint-Marin, le Royaume-Uni ainsi qu’Israël, les États-Unis d’Amérique et l’Union européenne.
La Convention-cadre vise à garantir que les activités menées aux différentes étapes du cycle de vie des systèmes d’intelligence artificielle sont pleinement compatibles avec les droits humains, la démocratie et l’État de droit, tout en étant favorable au progrès et aux innovations technologiques. Elle apporte des compléments aux normes internationales existantes relatives aux droits humains, à la démocratie et à l’État de droit et a surtout pour but de pallier à tout vide juridique qui pourrait résulter d’avancées technologiques rapides. Afin de résister au temps, la Convention-cadre ne régule pas la technologie et est neutre sur le plan technologique. Une conférence des parties fera office de commission exécutive du traité et facilitera la coopération entre les signataires.
La Convention-cadre du Conseil de l’Europe est critiquée par l’Assemblée parlementaire du Conseil de l’Europe, le Contrôleur européen de la protection des données et plusieurs organisations de la société civile du fait que, sous la pression de certains États membres ou observateurs (notamment les États-Unis, le Royaume-Uni, le Canada et le Japon), les obligations pesant sur les entreprises privées sont en réalité facultatives.
Les parties au traité ont en effet le choix entre appliquer la Convention-cadre aux acteurs privés ou bien traiter des risques et des impacts découlant des activités menées par les acteurs privés d’une manière conforme à l’objet et au but de la convention, en prenant « d’autres mesures pour se conformer aux dispositions du traité tout en respectant pleinement leurs obligations internationales en matière de droits de l’homme, de démocratie et d’État de droit ».
2. L’Alliance pour la gouvernance de l’IA proposée par le Forum économique mondial
Le Forum économique mondial a lancé une Alliance pour la gouvernance de l’IA. Déterminée à promouvoir une IA inclusive, éthique et durable, cette Alliance de 603 membres, dont 463 organisations, se concentre sur le développement des innovations, l’intégration des technologies d’IA dans les secteurs économiques et les impacts pratiques de l’adoption de l’IA.
Elle veille à la collaboration de plusieurs groupes de travail thématiques en vue d’accélérer les progrès technologiques et sociétaux avec des systèmes d’IA sûrs et avancés et de rationaliser la gouvernance de l’IA grâce à des cadres réglementaires solides et la promotion de normes techniques.
3. Des principes et bonnes pratiques proposés par les entreprises au Partnership on AI lancé en 2016 par sept géants de l’IA
Les entreprises, notamment les MAAAM, ont non seulement publié leurs propres principes et standards en matière d’IA (par exemple Google, Microsoft, Meta et Anthropic) qui prévoient des bonnes pratiques en amont du déploiement des systèmes d’IA (nettoyage des données, vigilance sur les sources et les données synthétiques ; recours à des évaluations et à des tests des modèles, y compris en red teaming ; lutte contre les biais ; alignement des modèles avec des principes éthiques) et en aval (politique de sécurité ; vigilance à la mise sur le marché et après ; transparence et accès aux sources par les RAG par exemple ; watermarking des contenus générés) mais elles ont aussi pris des initiatives en faveur de la gouvernance globale de l’IA.
Un Partnership on AI est créé en 2016. Fondée par Amazon, Facebook, Google, DeepMind, Microsoft et IBM, rejoints par Apple en 2017, cette association regroupe désormais plus d’une centaine de structures, non seulement des entreprises mais aussi des associations et des organismes du monde de la recherche, ainsi que des universitaires.
Selon sa propre définition, elle se présente comme un « centre de ressources pour les décideurs politiques, par exemple pour mener des recherches qui éclairent les meilleures pratiques en matière d’IA et pour explorer les conséquences sociétales de certains systèmes d’IA, ainsi que les politiques entourant le développement et l’utilisation de ces systèmes ».
Il a publié de nombreux articles, rapports et recommandations depuis sa création, dont, en 2023, un rapport sur l’utilisation des données synthétiques et un guide pour le déploiement de modèles de fondation sûrs. Google, Meta, Microsoft, Apple, OpenAI, le Alan Turing Institute et le Ada Lovelace Institute, ont, avec de nombreuses autres entreprises et organisations, fait part de leur soutien à ces travaux relatifs à la sécurité des modèles d’IA.
Le Partnership on AI est membre du consortium américain de l’AI Safety Institute, a le statut de membre du conseil consultatif de la société civile au sein du réseau des experts de l’OCDE et a eu le statut d’observateur au sein du comité chargé de la rédaction du traité international sur l’IA du Conseil de l’Europe.
4. Le Forum sur les modèles de pointe ou Frontier Model Forum et les autres initiatives
Créé en 2023, le Forum sur les modèles de pointe, ou Frontier Model Forum, est un partenariat restreint entre les entreprises américaines développant les systèmes d’IA les plus avancés : Microsoft, OpenAI, Google et Anthropic, qui se proposent de définir les conditions du développement d’IA sûres et responsables. Il s’agit en effet d’aider à :
– faire progresser la recherche sur la sécurité de l’IA afin de promouvoir le développement responsable des modèles de pointe et minimiser les risques potentiels ;
– identifier les meilleures pratiques de sécurité pour les modèles de pointe ;
– partager les connaissances avec les décideurs politiques, les universitaires, la société civile et d’autres pour faire progresser le développement responsable de l’IA ;
– soutenir les efforts visant à tirer parti de l’IA pour relever les plus grands défis sociétaux.
Le Forum vise aussi la divulgation responsable des vulnérabilités ou des capacités dangereuses au sein des modèles de pointe.
Le Forum a d’ores et déjà publié des notes. Les membres du Forum et leurs partenaires ont également créé un Fonds pour la sécurité de l’IA doté initialement de plus de 10 millions de dollars en vue de soutenir la recherche indépendante sur la sécurité de l’IA, comme de nouvelles évaluations des modèles et de nouvelles techniques de red teaming des modèles d’IA. Ce Fonds se veut un élément de l’accord sur les engagements volontaires en matière d’IA signé à la Maison-Blanche dans le cadre de l’Executive Order de 2023. Le 1er avril 2024, le Forum a annoncé qu’il avait accordé la première série de subventions au titre du Fonds.
De son côté, Meta a créé en décembre 2023 avec IBM et plus de 50 membres fondateurs une Alliance pour l’IA (AI Alliance). Ils ont été rejoints par 20 autres membres en avril 2024. Cette initiative se singularise par sa volonté de promouvoir la science ouverte et l’innovation ouverte en IA. Elle a déjà mis en place des groupes de travail (l’un porte sur les outils de sécurité et de confiance, l’autre sur les politiques publiques).
Le consortium MLCommons lancé en 2020 est quant à lui composé de 125 membres et vise la coopération dans la communauté du Machine Learning. Il a produit un benchmarck apprécié des aspects software et hardware de l’apprentissage machine et offre des jeux de données et des outils utiles à tous les chercheurs. Il se propose également de définir les bonnes pratiques et les normes des systèmes d’IA relevant du Machine Learning. En 2023, ce consortium a lancé un groupe de travail sur la sécurité des systèmes d’IA, avec un intérêt pour l’évaluation des LLM selon le cadre proposé par le CRFM de Stanford. Anthropic, Coactive AI, Google, Inflection, Intel, Meta, Microsoft, Nvidia, OpenAI, Qualcomm Technologies sont, avec d’autres entreprises, au sein de ce groupe de travail qui a annoncé une première preuve de concept (Proof of Concept) en avril 2024.
Microsoft a initié en 2021 une association autour de l’origine des contenus, la Coalition for Content Provenance and Authenticity (C2PA), avec Adobe, Arm, BBC, Intel, and Truepic. Depuis, de nombreuses entreprises comme Google, OpenAI, xAI ou Sony, ont rejoint la C2PA.
Microsoft et OpenAI ont créé en 2024 un fonds pour la résilience sociétale, le Societal Resilience Fund, qui avec 2 millions de dollars vise à encourager l’éducation et la connaissance de l’IA auprès des électeurs et des communautés fragiles. Ce fonds sert par exemple à verser des subventions à des associations conduisant des projets éducatifs comme le Partnership on AI ou la C2PA.
Toujours en 2024 a été créée la Tech Coalition, autour d’Adobe, Amazon, Bumble, Google, Meta, Microsoft, OpenAI, Roblox, Snap Inc. et TikTok. Ce groupe finance des recherches sur la pédopornographie, l’exploitation d’enfants et les abus sexuels en ligne en lien avec l’IA générative.
Enfin, un Tech Accord to Combat Deceptive Use of AI in Elections, un accord pour lutter contre l’utilisation trompeuse de l’IA lors des élections, réunit, depuis février 2024, 20 signataires, dont Google, Meta, Microsoft, IBM, xAI, Anthropic, OpenAI et StabilityAI autour d’un ensemble de huit engagements pour lutter contre la désinformation politique par l’IA, notamment dans le cadre des élections qui doivent se tenir dans plus de 40 pays en 2024.
Au total, il faut retenir cette volonté des entreprises du secteur de l’IA de s’organiser en groupes sectoriels, soit pour servir de centre de ressources aux décideurs politiques comme le Partnership on AI, soit pour soutenir la recherche sur la sécurité de l’IA, identifier les bonnes pratiques pour les modèles de pointe et partager les connaissances avec les parties prenantes, comme le Frontier Model Forum. Certaines initiatives visent des aspects plus thématiques : éducation, science ouverte, authenticité des contenus, pédopornographie, désinformation à caractère politique, etc.
Toutes ces démarches sont des exemples d’autorégulation comme l’a expliqué Florence G’sell mais l’on peut déplorer qu’elles ne conduisent pas, le plus souvent, à des normes précises et encore moins à des règles juridiquement contraignantes. Leur intérêt réside peut-être plutôt dans leur capacité volontaire ou non à fournir des informations précieuses aux législateurs et régulateurs qui envisagent des cadres juridiques contraignants pour les systèmes d’IA.
1. Un réseau international d’agences pour la sécurité de l’intelligence artificielle
Les sommets pour la sécurité de l’intelligence artificielle (en anglais, AI safety summits) sont des conférences internationales d’initiative britannique visant à anticiper et encadrer les risques potentiels liés à l’intelligence artificielle. Elles ont conduit plusieurs pays, après le Royaume-Uni et les États-Unis en novembre 2023, à mettre en place des AI Safety Institutes.
Le Canada, l’Australie, le Japon, la Corée du Sud, Singapour, le Kenya, la France et l’UE ont ainsi rejoint les États-Unis et le Royaume-Uni au sein d’une nouvelle coordination internationale, appelée « International Network of Cooperation of the National AI Safety Institutes » (AISI), dont la première réunion s’est tenue à San Francisco les 21 et 22 novembre 2024, réunissant les experts de neuf pays et de l’Union européenne.
La secrétaire américaine au commerce, Gina Raimondo avait annoncé la naissance de ce réseau lors du sommet pour la sécurité de l’intelligence artificielle organisé par la Corée du Sud à Séoul en mai 2024. La réunion de San Francisco a permis le lancement effectif et les modalités de cette coopération internationale des AISI en vue d’avancer concrètement en termes de sécurité de l’IA, de normes techniques, d’échanges de bonnes pratiques et de partage de connaissances.
2. Du sommet de Bletchley Park au rapport de Yoshua Bengio
Ces sommets sont relativement récents, la première édition ayant eu lieu en novembre 2023 à Bletchley Park, situé à mi-chemin d’Oxford et de Cambridge, lieu symbolique pour l’informatique et l’IA car associé à la mémoire d’Alan Turing. Ils réunissent à la fois des chefs d’États et de gouvernements, mais également des représentants d’organisations internationales comme Antonio Guterres, secrétaire général de l’ONU, et des représentants d’entreprises privées comme Elon Musk ainsi que du monde de la recherche comme Yoshua Bengio.
Les cinq objectifs du premier sommet étaient de parvenir à un consensus sur les risques associés à l’IA de pointe ; de faire progresser la coopération internationale par le biais de cadres de travail nationaux et internationaux ; de déterminer des mesures de sécurité adaptées aux entreprises du secteur privé ; d’identifier des domaines de recherche collaborative en matière de sécurité de l’IA ; et de mettre en lumière les aspects bénéfiques de l’IA.
Le premier sommet, dont une partie des discussions a été rendue publique, a débouché sur la rédaction d’une déclaration commune de l’ensemble des participants appelée « la Déclaration de Bletchley ». Cette déclaration, plutôt pessimiste, a souligné le besoin urgent d’une collaboration internationale pour gérer les risques potentiels associés aux systèmes d’IA de pointe et a reconnu l’existence de risques existentiels pour l’humanité qui pourraient être induits par un développement rapide et non maîtrisé de l’intelligence artificielle. La déclaration appelle ainsi à se concentrer sur la notion de sécurité de l’intelligence artificielle tout au long de sa chaîne de valeur lors des prochains sommets, organisés de façon semestrielle.
Le sommet a également débouché sur une déclaration relative aux tests de sécurité, signée par l’Union européenne, dix pays (États-Unis, Royaume-Uni, France, Allemagne, Italie, Canada, Australie, Japon, Corée du Sud et Singapour) et des entreprises d’IA de premier plan, telles que OpenAI, Google, Anthropic, Amazon, Mistral, Microsoft et Meta, qui pourront s’engager à soumettre leurs modèles de pointe aux gouvernements pour qu’ils réalisent des tests de sécurité. Le document qui n’est pas juridiquement contraignant réitère qu’il incombe aux gouvernements de financer ces tests et d’évaluer les nouveaux modèles d’IA développés par les entreprises avant leur mise sur le marché. Il invite à se concentrer sur les évaluations des « risques liés à la sécurité nationale », plutôt que sur les dommages potentiels causés par les utilisations au quotidien.
Ces discussions ont également conduit à établir un groupe international de 75 experts de 30 pays chargé de rédiger un rapport annuel sur la politique et la régulation de l’IA, selon un format proche de celui utilisé par le Groupe d’experts intergouvernemental sur l’évolution du climat (GIEC). Le Partenariat mondial sur l’intelligence artificielle (PMIA ou, en anglais, Global partnership on artificial intelligence ou GPAI) le propose aussi et en octobre 2023, Eric Schmidt, ancien PDG de Google, avec plusieurs autres dirigeants du secteur, avait également proposé un tel groupe d’experts.
Le sommet de Bletchley Park a, enfin, demandé plus spécifiquement la préparation par ce groupe, en vue du prochain sommet, d’un rapport précis sur l’état de la science concernant l’IA de pointe (« State of the Science Report on Frontier AI »).
Le sommet suivant s’est déroulé six mois plus tard, en mai 2024, en visioconférence et en présentiel à Séoul et a donné lieu à la publication d’un rapport scientifique international sur la sécurité de l’IA dirigé par Yoshua Bengio, que ce dernier a pu présenter aux rapporteurs lors de son audition.
Il a affirmé que la préparation de ce rapport a permis de réunir une sorte d’équivalent du GIEC mais pour l’IA et a fourni une évaluation actualisée et scientifiquement fondée de la sécurité des systèmes d’IA de pointe. Ce document est destiné aux décideurs publics et vulgarise les connaissances scientifiques dans le domaine.
Le rapport met en évidence plusieurs points clés concernant les modèles d’IA avancés. Il met l’accent sur la double nature de l’IA, son potentiel pour améliorer le bien-être, l’économie et la science mais aussi ses dangers : l’utilisation malveillante de l’IA peut entraîner de la désinformation à grande échelle, des opérations d’influence, des fraudes et des escroqueries, tandis que des systèmes d’IA défectueux pourraient produire des décisions biaisées affectant des groupes ou des personnes à raison de leur race, sexe, culture, âge ou handicap. Si les capacités de l’IA progressent rapidement, des défis fondamentaux demeurent pour les chercheurs comme la compréhension du fonctionnement interne des IA ou ses modes de raisonnement, son rapport à la causalité par exemple.
Le rapport souligne l’incertitude qui entoure l’avenir de l’IA, avec de nombreux scénarios possibles : une évolution lente ou des progrès extrêmement rapides entraînant des risques systémiques (perturbations du marché du travail et inégalités économiques), voire des risques existentiels (perte de contrôle de l’IA et conséquences catastrophiques sur l’humanité). Si des méthodes techniques, telles que des tests, le red teaming et l’audit des données d’entraînement, peuvent atténuer certains risques, elles ont des limites et ne permettent pas de traiter l’ensemble des risques.
Le sommet de Séoul a également été l’occasion pour 16 entreprises d’IA de s’engager à se doter d’un référentiel en matière de sécurité et de structures de contrôle et de gouvernance.
En clôture de la réunion, le Royaume-Uni et la Corée du Sud, hôtes du sommet, ont obtenu des participants l’engagement de poursuivre et d’approfondir la recherche sur la sécurité de l’IA et les seuils de risque pour les modèles de pointe.
Des pays, comme l’Italie ou l’Allemagne, signataires de la déclaration finale du sommet de Séoul en faveur de la coopération internationale en matière de sécurité d’IA, ont, en outre, fait part de leur volonté de rejoindre le réseau des AISI (International Network of Cooperation of the National AI Safety Institutes). Cependant, une annonce de septembre 2024 du secrétaire d’État américain Antony Blinken expliquait que le Kenya serait le seul nouveau membre du réseau à ce stade.
